ForePaaSで公開データから機械学習モデルを構築する手順 ~Part2~

ForePaaS解説
コラム


更新日:2022年12月21日
このコラムは日本ビジネスシステムズ株式会社(JBS)がForePaaSを使ってみた流れを記載したものとなっています。データ利活用プラットフォームであるForePaaSの機能を理解するため、公開データを収集・加工し機械学習アルゴリズムを利用した予測モデルを構築します。ForePaaSの使い方やできることのイメージが伝わればと思います。
今回はボートレースの公開情報を収集し、着順予想のモデルを構築します。
※モデルのスコアを実用性のある精度にすることは本記事の対象としていません。
今回はボートレースの公開情報を収集し、着順予想のモデルを構築します。
※モデルのスコアを実用性のある精度にすることは本記事の対象としていません。
全体の記事
以下のようにPartを分けて記事を投稿していきます。今回はPart2のテーブルのデータ加工とクエリ作成を行います。Part1をまだ読んでいない方は、先にPart1を読んだ後にこの記事を読むことをおすすめします。
■ForePaaSへの (1)データ取り込み、(2)データ加工、(3)データ分析 に関する概要
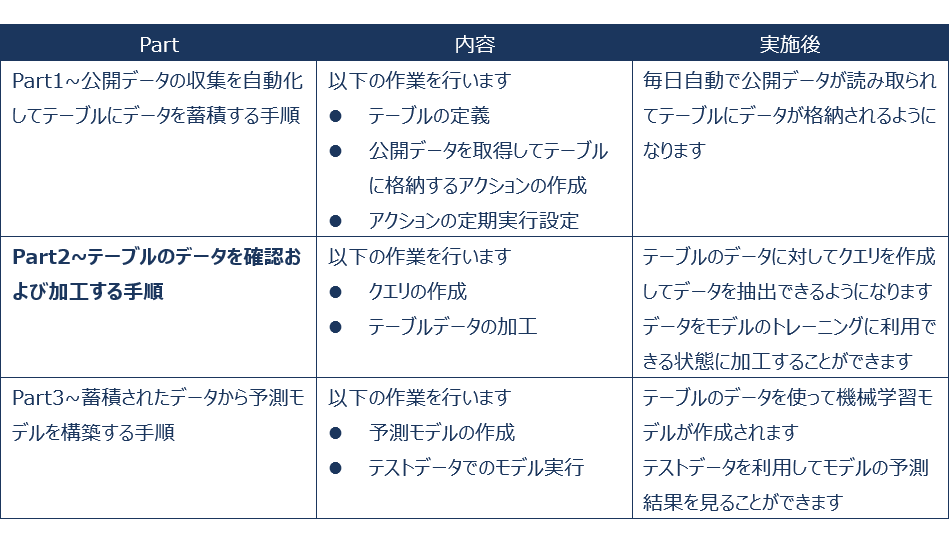
1. 今回のPartの概要
1.1. 学習用データの準備
今回は機械学習モデル作成に向けて、モデルが学習するために必要なデータを準備します。モデルに期待することは着順予測であるため、前回取得した番組表のデータをインプットとして着順を予測するモデルの作成が全体のゴールとなります。そして、モデルが判断ロジックを学習するために学習用データを準備する必要があります。
番組表のデータに競争成績のデータからそれぞれの着順の情報を加えたデータをモデルの学習用データとして準備します。Part2はそのデータの準備を行いましょう。
■機械学習モデル作成の大まかな流れ
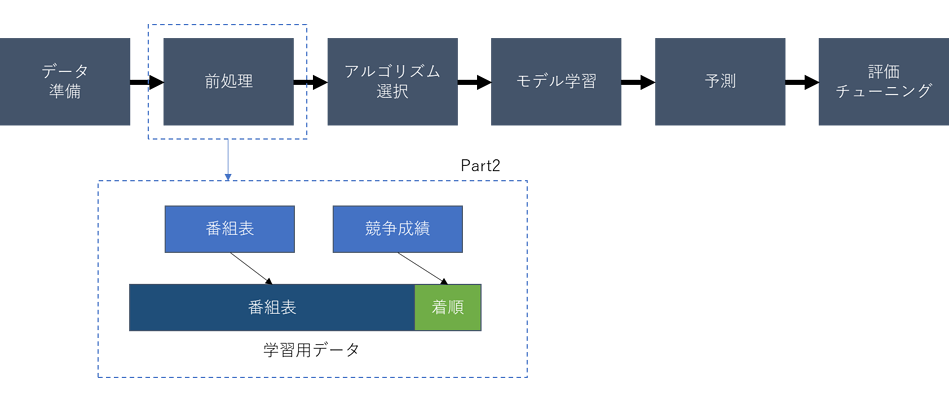
1.2. 手順概要
Part1ではForePaaSでの処理として「アクション」を作成しました。今回はPart1で取得した競争成績と番組表のデータから、各選手がそのレースで2着以内だったかを計算してデータに加え、モデル学習用のテーブルに追加するアクションを作成したいと思います。ForePaaSに用意されているデータ集計用のAggregateアクションを利用します。
※ボートレースの舟券には複勝(選んだボートが2着以内だったか)というものがあります。
ボートレースは、1レース6艇で順位を競うため、2着以内ということは3分の1で的中する払い戻しの少ない買い方です。本当は全ての着順を予想してみたいのですが、まずはシンプルな2着以内か、否かを判定する2値分類を利用してみたいと思います。
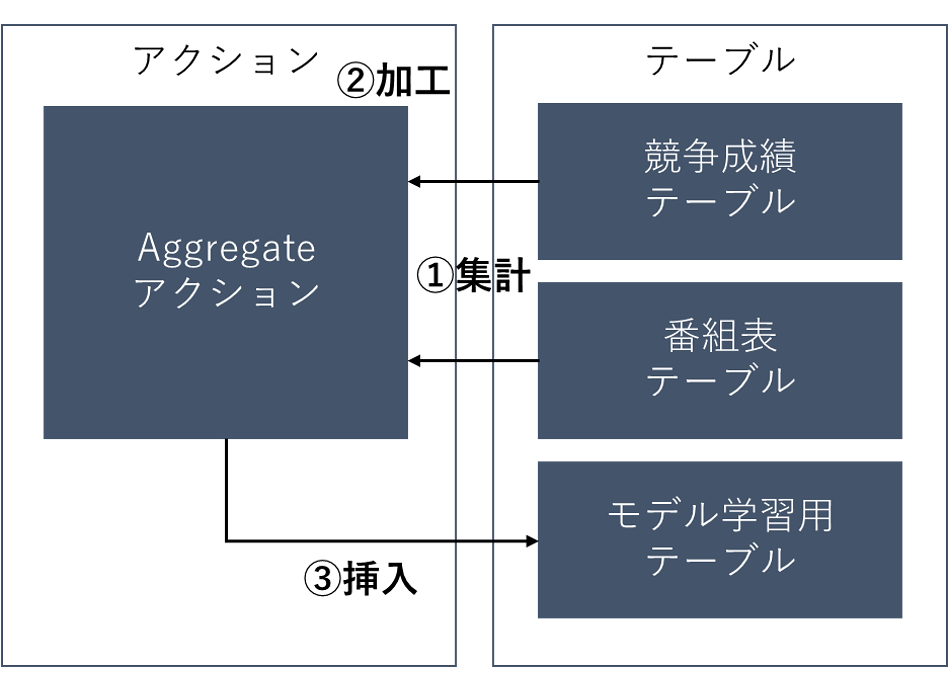
Aggregateアクション
Aggregateアクションは1つ以上の既存のテーブルから任意のテーブルへデータを集計するアクションです。SQL利用して、データを加工しながら集計することができます。
Aggregateアクションの処理の流れ
①番組表テーブルと競争成績テーブルからデータを取得
②2着以内かを判定して集計
③モデル学習用テーブルに挿入
■テーブルイメージ
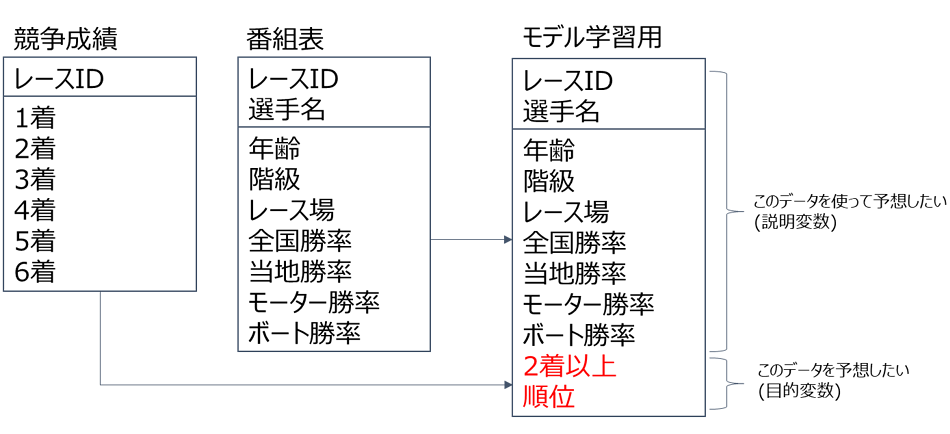
■Aggregateアクションの処理の流れ
番組表のデータに競争成績のデータからそれぞれの着順の情報を加えたデータをモデルの学習用データとして準備します。Part2はそのデータの準備を行いましょう。
■機械学習モデル作成の大まかな流れ
※ボートレースの舟券には複勝(選んだボートが2着以内だったか)というものがあります。
ボートレースは、1レース6艇で順位を競うため、2着以内ということは3分の1で的中する払い戻しの少ない買い方です。本当は全ての着順を予想してみたいのですが、まずはシンプルな2着以内か、否かを判定する2値分類を利用してみたいと思います。
②2着以内かを判定して集計
③モデル学習用テーブルに挿入
■テーブルイメージ
■Aggregateアクションの処理の流れ
2. 手順
目次
2.1. モデル学習用テーブルを作成する
今回作成するモデル学習用テーブルは番組表テーブルをもとにしたテーブルであるため、複製機能を利用してテーブルを作成し、2着以内かの列を追加しましょう。
(1)[DATA MANAGER]にアクセスします。
(2)[TABLES]にアクセスし、見やすいように右上の表示形式でリスト形式を選択します。
■ForePaaS操作画面(TABLES)
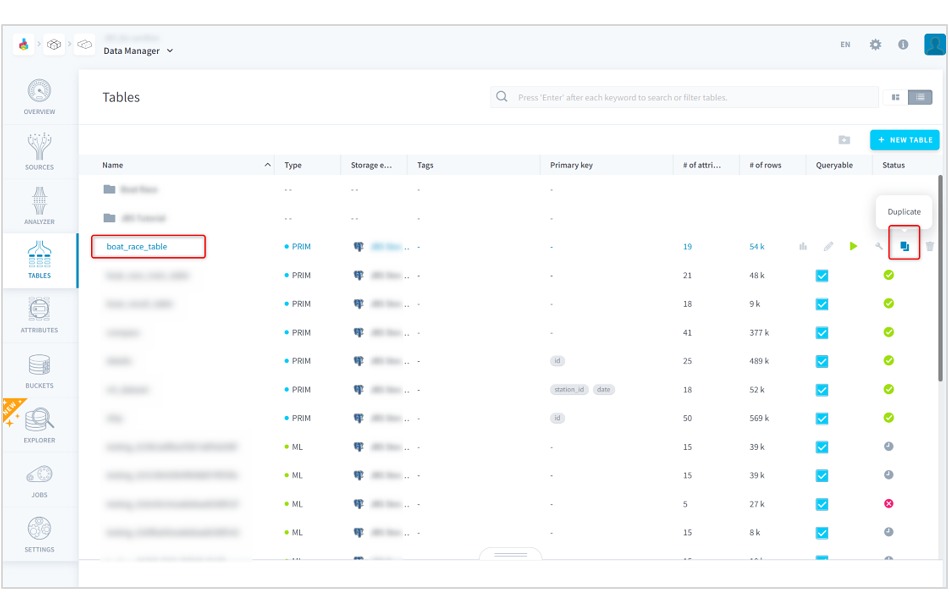
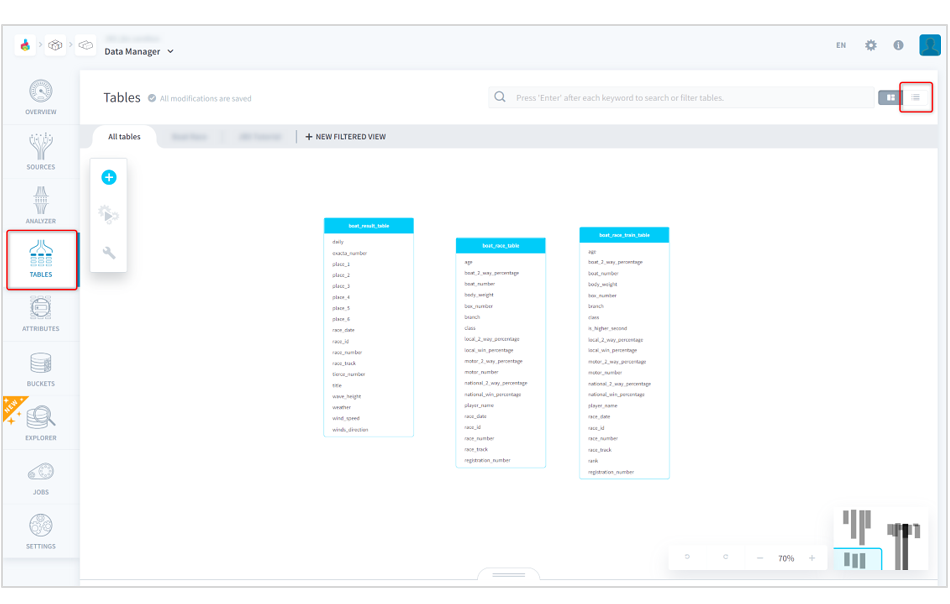 (3)番組表テーブルとして作成した「boat_race_table」の右にある複製をクリックします。
(3)番組表テーブルとして作成した「boat_race_table」の右にある複製をクリックします。
■ForePaaS操作画面(TABLES)番組表テーブル複製1
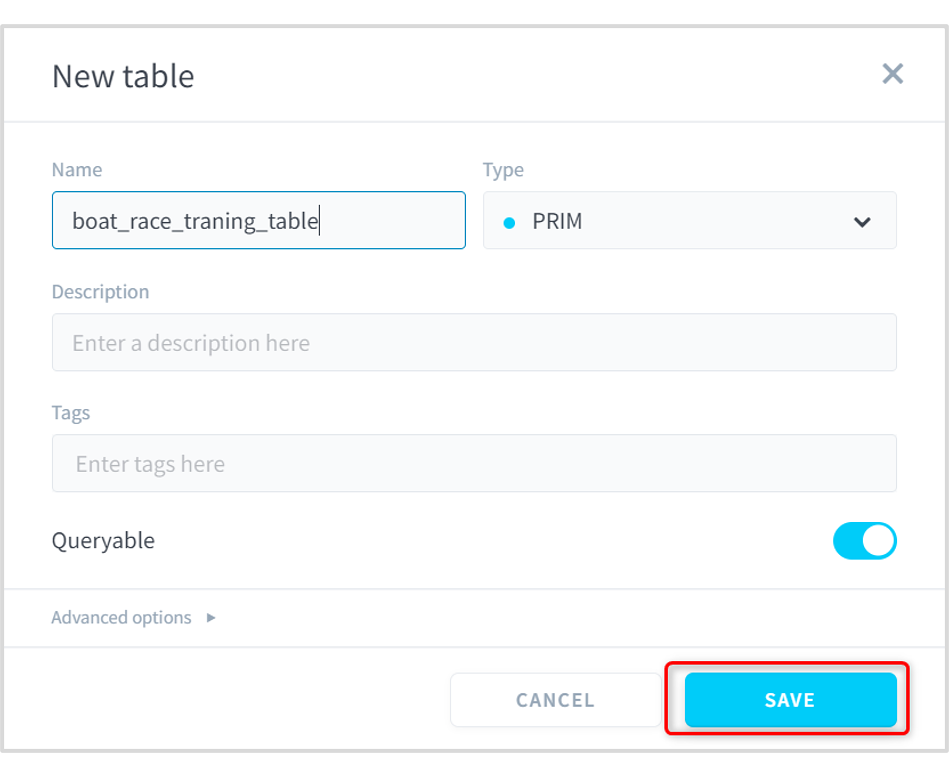
 (4)[Name]に任意の名前を入力して[SAVE]をクリックします。
(4)[Name]に任意の名前を入力して[SAVE]をクリックします。
■ForePaaS操作画面(TABLES)番組表テーブル複製2
 (5)番組表と同じテーブル定義でテーブルが作成されるので、作成されたテーブルの[Infos]をクリックします。
(5)番組表と同じテーブル定義でテーブルが作成されるので、作成されたテーブルの[Infos]をクリックします。
■ForePaaS操作画面(TABLES)テーブル作成1
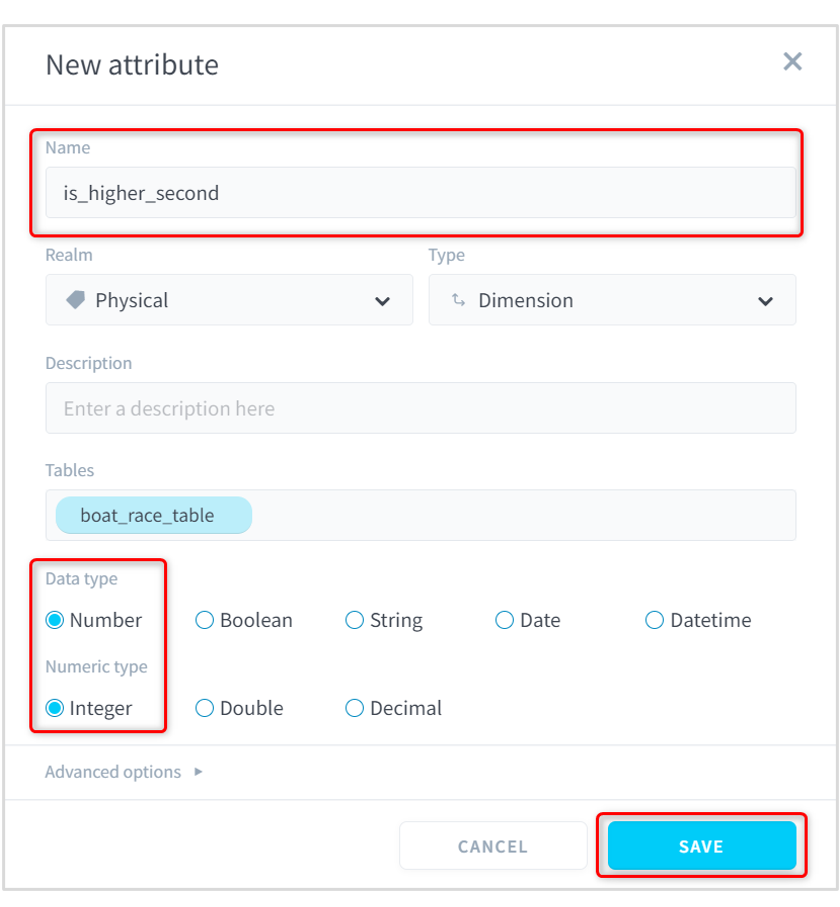
 (6)[NEW ATTRIBUTE]をクリックします。
(6)[NEW ATTRIBUTE]をクリックします。
(7)以下の内容を入力して[SAVE]をクリックします。
Name:is_higher_second
Data type:Number
Numeric type:Integer
■ForePaaS操作画面(TABLES)テーブル作成2
 (8)テーブルの右にある[Build]をクリックします。
(8)テーブルの右にある[Build]をクリックします。
■ForePaaS操作画面(TABLES)テーブル作成3
 これで番組表データ+2着以上であるかどうかの情報を持ったモデル学習用テーブルが作成されました。
これで番組表データ+2着以上であるかどうかの情報を持ったモデル学習用テーブルが作成されました。
2.2. データ集計用のAggregateアクションを作成する
先ほどテーブルを定義してビルドしましたが、まだ何もデータが入っていません。番組表のデータと着順の情報を計算してテーブルに追加してあげる必要があります。Aggregateアクションを作成します。
(1)[DATA PROCESSING ENGINE]にアクセスします。
(2)[ACTIONS]にアクセスし、[NEW ACTION]をクリックします。
(3)[Aggregate]を選択し、[SELECT]をクリックします。
(4)[Add a source]をクリックし、番組表テーブルのboat_race_tableをクリックします。
(5)再度 [Add a source]をクリックし、競争成績テーブルのboat_result_tableをクリックします。
(6)内部結合の条件に以下を入力します。
Add a sourceで複数のテーブルを選択することで、それらのテーブルを結合した情報をもとに集計することができます。結合の種類はデフォルトで内部結合が選択されています。内部結合は、特定のフィールドの値が一致するレコードについて、両方のテーブルに存在するデータを抽出します。
ここで入力している条件は内部結合でどのフィールドの値が一致していれば結合するかの条件を入力しています。
■ForePaaS操作画面(Data Processing Engine)コード入力
 (7)[Add a destination]をクリックし、先ほど作成したモデル学習用テーブルをクリックします。
(7)[Add a destination]をクリックし、先ほど作成したモデル学習用テーブルをクリックします。
■ForePaaS操作画面(ACTIONS)モデル学習用テーブル選択
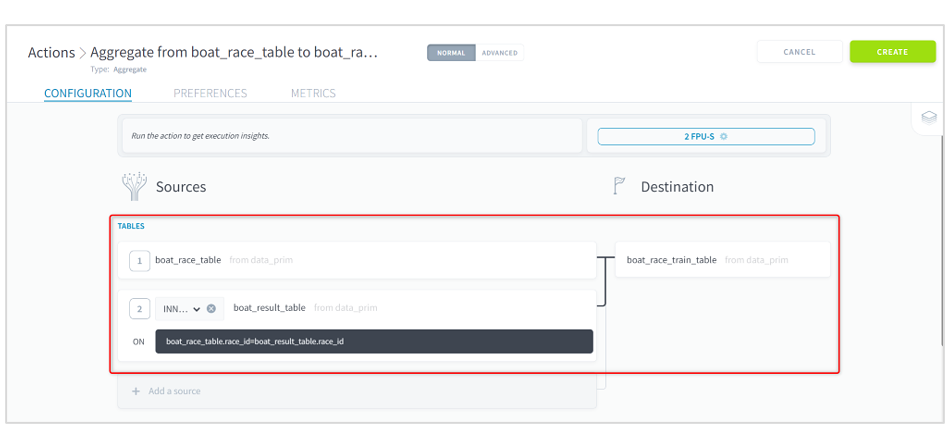 これで、レースIDをもとに番組表テーブルと競争成績が内部結合されたデータを使ってモデル学習用テーブルにデータを集計する状態となりました。
これで、レースIDをもとに番組表テーブルと競争成績が内部結合されたデータを使ってモデル学習用テーブルにデータを集計する状態となりました。
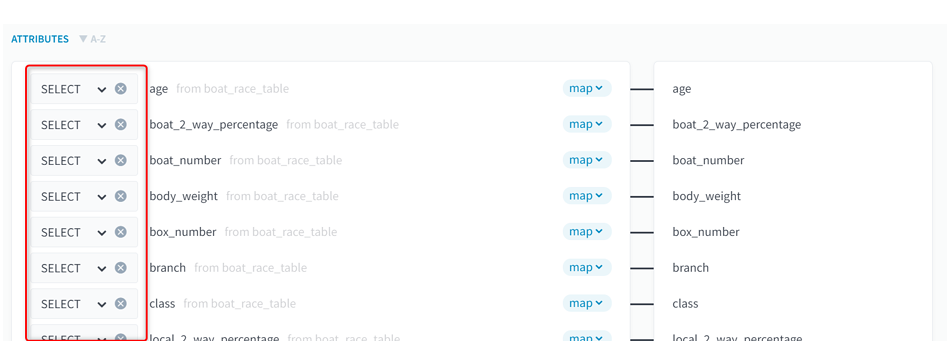
(8)全てのデータのMAXをSELECTに変更します。
■ForePaaS操作画面(ACTIONS)データ設定変更
 (9)is_higher_secondのmapをsqlに変更します。
(9)is_higher_secondのmapをsqlに変更します。
Aggregateアクションは1つ以上のテーブルから別のテーブルへデータを集めて移動することができます。
各データに対してデータの移動方法を指定することができ、3つの方法が用意されています。
・map:集計元となるデータをSELECT、SUM、MAXなどから選択してデータを追加します
・sql:入力されたSQL文を実行しデータを追加します
・text:入力したテキストをそのままデータとして追加します
Is_higher_secondは順位に応じて2着以上であるかどうかをデータに追加したいため、条件文を入力できるsqlを利用します。今回は行いませんが、レース場や階級などのカテゴリーとなるデータを数値に変換したりなど、学習用データを作る簡単な前処理をSQL文で書くことができます。
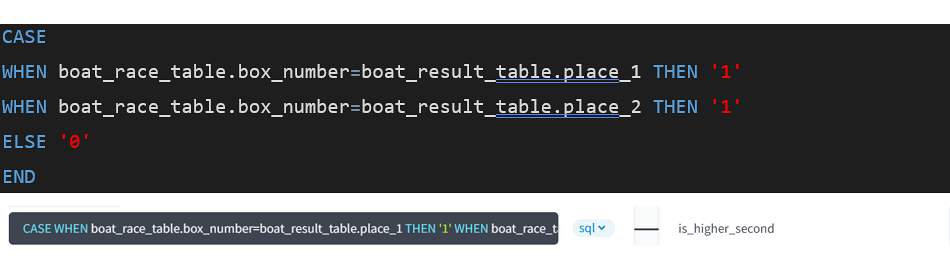
(10)SQL文に以下を入力します。
これは、各レコードの艇番が競争成績の1位か2位である場合は1、そうでない場合は0を入れるというものです。
■ForePaaSソースコード解説_アクション追加
 (11)任意のアクション名を入力し、[CREATE]をクリックします。
(11)任意のアクション名を入力し、[CREATE]をクリックします。
(12)[RUN]をクリックします。
(13)[DATA MANAGER]にアクセスします。
(14)[TABLES]にアクセスし、見やすいように右上の表示形式でリスト形式を選択します。
(15)モデル学習用テーブルの右側にデータ量が表示されるので、データがきちんと入力されていることを確認します。
■ForePaaS操作画面(TABLES)データ情報確認
 これで、モデル学習用テーブルのデータが完成しました。
これで、モデル学習用テーブルのデータが完成しました。
2.3. クエリを作成してデータを確認する
クエリを作成して先ほど作成したデータを実際に見てみましょう。データの傾向を簡単にグラフ化して確認することができます。ここで作成したクエリはそのままダッシュボードアプリケーションを作成するときに表示するグラフとして利用することができます。
ボートレースで特徴的な艇番による着順の傾向を見てみましょう。
(1)[Analytics Manager]にアクセスします。
(2)[QUERIES]にアクセスし、[NEW QUERY]をクリックします。
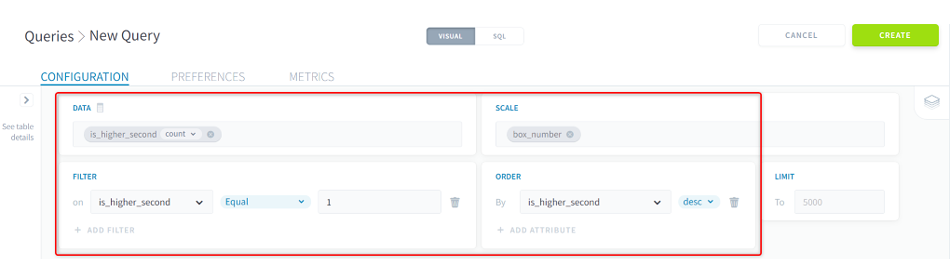
(3)[DATA]でis_higher_secondを選択し、selectをcountに変更します。
(4)[SCALE]にはbox_numberを選択します。
(5)[FILTER]にはis_higher_secondを選択し、値を1とします。傾向を見たいため、2着以上になった結果と艇番との関係を見ます。
(6)[ORDER]にはis_higher_secondを選択し、ascをdescに変更します。
■ForePaaS操作画面(QUERIES)作成データ確認
 (7)[RUN]をクリックします。
(7)[RUN]をクリックします。
(8)表形式から棒グラフに切り替えます。
■ForePaaS操作画面(QUERIES)作成データ 棒グラフ表示1
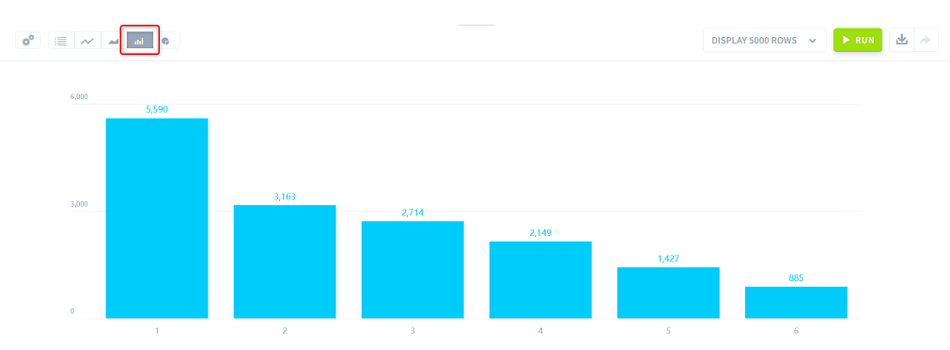 艇番が1の場合2着以上のデータが1番多く、艇番が小さいものから順番に並び、艇番が6の場合は2着以上になるデータが1番少ないことがわかります。
艇番が1の場合2着以上のデータが1番多く、艇番が小さいものから順番に並び、艇番が6の場合は2着以上になるデータが1番少ないことがわかります。
1号艇は1番内側からスタートするため最初にターンマークを周ることができ、他のボートは別のボートによって起こされた波のある水面をターンしなければいけないですが、1号艇はその影響を受けません。そして外側であればあるほど、ターンの際に壁となるボートが増えるため、追い抜かすためには技術が必要となります。
他の公営競技と異なる「1号艇が圧倒的に有利であること」、「インコースが強い」という特徴がグラフからも見て取れます。FILTERの値を0にすると逆の関係になることもわかります。
クラスによる着順の傾向を見てみましょう。
(9)先ほどのクエリのまま[SCALE]のbox_numberを削除してclassを選択し、[RUN]をクリックします。
■ForePaaS操作画面(QUERIES)作成データ 棒グラフ表示2
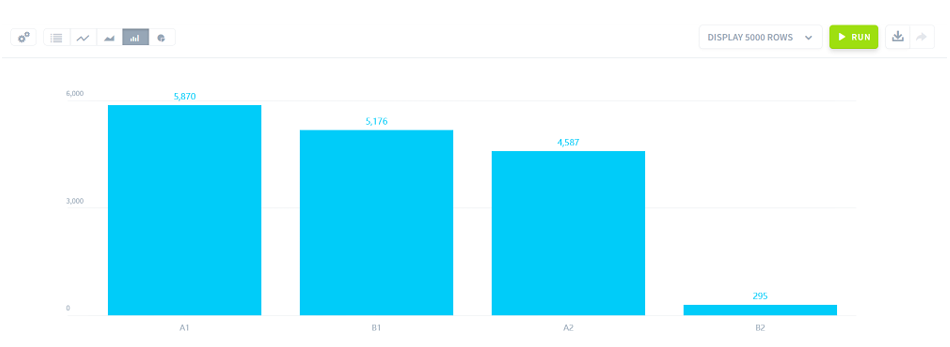 結果は皆さんが取得しているデータの日付によって変わりますが、おそらくA1が多くB2が少ない結果になると思います。ですが、先ほどの必ず1~6まで存在する艇番と違って、階級はA1の選手がたくさん出場したから単純にA1の2着以上のデータが多い可能性があります。
結果は皆さんが取得しているデータの日付によって変わりますが、おそらくA1が多くB2が少ない結果になると思います。ですが、先ほどの必ず1~6まで存在する艇番と違って、階級はA1の選手がたくさん出場したから単純にA1の2着以上のデータが多い可能性があります。
※ボートレースの階級について
ボートレースの選手は階級が4つのランクに分かれており半年に1回更新されます。主に勝率(1着になる確率)、2連対率(2着以内になる確率)、3連対率(3着以内になる確率)と事故率や最低出走回数によってランク付けされます。勝率によって分けられるため、ランクの高い選手はランクの低い選手より良い成績になる可能性が高いと予想できます。実際のレースでもB1の選手は選択肢から除外する、1号艇がA1の選手の場合本命とするなど、階級が予想に使用されています。
(10)[DATA]、[SCALE]、[FILTER]を以下のように設定し、[RUN]をクリックします。
DATA:class/count
SCALE:is_higher_second
FILTER:class Equal A1
(11)円グラフ形式に変更します。
■ForePaaS操作画面(QUERIES)作成データ 円グラフ表示1
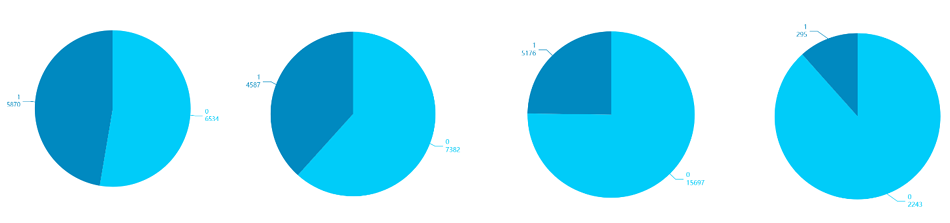
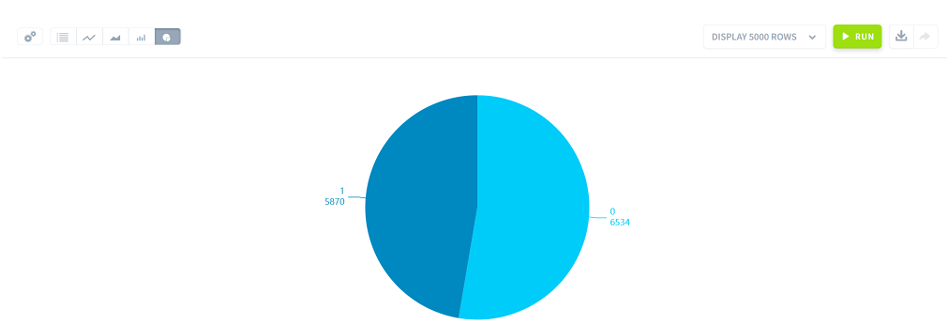 FILTERの値をA1、A2、B1、B2と変更するとわかりますが、A1、A2、B1、B2の順番で2着以上になったデータが多いことがわかります。画像は左からA1、A2、B1、B2の円グラフです。クラスによる傾向がわかります。
FILTERの値をA1、A2、B1、B2と変更するとわかりますが、A1、A2、B1、B2の順番で2着以上になったデータが多いことがわかります。画像は左からA1、A2、B1、B2の円グラフです。クラスによる傾向がわかります。
■ForePaaS操作画面(QUERIES)作成データ 円グラフ表示2
 テーブルの情報から簡単に結果を取得してグラフ化して見ることができました。このAnalytics Managerでデータを自由に探索し、結果を報告する、さらにデータに必要な加工を行う、傾向を確認する、ダッシュボードに表示するなど、さまざまな目的に活用することができます。
テーブルの情報から簡単に結果を取得してグラフ化して見ることができました。このAnalytics Managerでデータを自由に探索し、結果を報告する、さらにデータに必要な加工を行う、傾向を確認する、ダッシュボードに表示するなど、さまざまな目的に活用することができます。
これでPart2の記事は終了となります。
2.4. 次回のPart
今回のPart2で、予想したい「2着以内か」というデータと予想するための材料となるデータを1つのテーブルに格納しました。このデータをクエリで分析するだけでも傾向が見えて予想に活用できますが、コンピュータにデータを学習させてパターンやルールを見つけ出すことでさらに精度の高い予想を出力できる可能性があります。
次回のPart3では、まず材料となるデータの中で、本当に必要なデータはどれか、予想に悪影響を与える余計な材料はどれかを分析します。そして必要なデータのみを使って学習したモデルを構築し、実際の予想結果を見てみましょう。
(1)[DATA MANAGER]にアクセスします。
(2)[TABLES]にアクセスし、見やすいように右上の表示形式でリスト形式を選択します。
■ForePaaS操作画面(TABLES)
■ForePaaS操作画面(TABLES)番組表テーブル複製1
■ForePaaS操作画面(TABLES)番組表テーブル複製2
■ForePaaS操作画面(TABLES)テーブル作成1
(7)以下の内容を入力して[SAVE]をクリックします。
Name:is_higher_second
Data type:Number
Numeric type:Integer
■ForePaaS操作画面(TABLES)テーブル作成2
■ForePaaS操作画面(TABLES)テーブル作成3
(1)[DATA PROCESSING ENGINE]にアクセスします。
(2)[ACTIONS]にアクセスし、[NEW ACTION]をクリックします。
(3)[Aggregate]を選択し、[SELECT]をクリックします。
(4)[Add a source]をクリックし、番組表テーブルのboat_race_tableをクリックします。
(5)再度 [Add a source]をクリックし、競争成績テーブルのboat_result_tableをクリックします。
(6)内部結合の条件に以下を入力します。
Add a sourceで複数のテーブルを選択することで、それらのテーブルを結合した情報をもとに集計することができます。結合の種類はデフォルトで内部結合が選択されています。内部結合は、特定のフィールドの値が一致するレコードについて、両方のテーブルに存在するデータを抽出します。
ここで入力している条件は内部結合でどのフィールドの値が一致していれば結合するかの条件を入力しています。
■ForePaaS操作画面(Data Processing Engine)コード入力
■ForePaaS操作画面(ACTIONS)モデル学習用テーブル選択
(8)全てのデータのMAXをSELECTに変更します。
■ForePaaS操作画面(ACTIONS)データ設定変更
Aggregateアクションは1つ以上のテーブルから別のテーブルへデータを集めて移動することができます。
各データに対してデータの移動方法を指定することができ、3つの方法が用意されています。
・map:集計元となるデータをSELECT、SUM、MAXなどから選択してデータを追加します
・sql:入力されたSQL文を実行しデータを追加します
・text:入力したテキストをそのままデータとして追加します
Is_higher_secondは順位に応じて2着以上であるかどうかをデータに追加したいため、条件文を入力できるsqlを利用します。今回は行いませんが、レース場や階級などのカテゴリーとなるデータを数値に変換したりなど、学習用データを作る簡単な前処理をSQL文で書くことができます。
(10)SQL文に以下を入力します。
これは、各レコードの艇番が競争成績の1位か2位である場合は1、そうでない場合は0を入れるというものです。
■ForePaaSソースコード解説_アクション追加
(12)[RUN]をクリックします。
(13)[DATA MANAGER]にアクセスします。
(14)[TABLES]にアクセスし、見やすいように右上の表示形式でリスト形式を選択します。
(15)モデル学習用テーブルの右側にデータ量が表示されるので、データがきちんと入力されていることを確認します。
■ForePaaS操作画面(TABLES)データ情報確認
ボートレースで特徴的な艇番による着順の傾向を見てみましょう。
(1)[Analytics Manager]にアクセスします。
(2)[QUERIES]にアクセスし、[NEW QUERY]をクリックします。
(3)[DATA]でis_higher_secondを選択し、selectをcountに変更します。
(4)[SCALE]にはbox_numberを選択します。
(5)[FILTER]にはis_higher_secondを選択し、値を1とします。傾向を見たいため、2着以上になった結果と艇番との関係を見ます。
(6)[ORDER]にはis_higher_secondを選択し、ascをdescに変更します。
■ForePaaS操作画面(QUERIES)作成データ確認
(8)表形式から棒グラフに切り替えます。
■ForePaaS操作画面(QUERIES)作成データ 棒グラフ表示1
1号艇は1番内側からスタートするため最初にターンマークを周ることができ、他のボートは別のボートによって起こされた波のある水面をターンしなければいけないですが、1号艇はその影響を受けません。そして外側であればあるほど、ターンの際に壁となるボートが増えるため、追い抜かすためには技術が必要となります。
他の公営競技と異なる「1号艇が圧倒的に有利であること」、「インコースが強い」という特徴がグラフからも見て取れます。FILTERの値を0にすると逆の関係になることもわかります。
クラスによる着順の傾向を見てみましょう。
(9)先ほどのクエリのまま[SCALE]のbox_numberを削除してclassを選択し、[RUN]をクリックします。
■ForePaaS操作画面(QUERIES)作成データ 棒グラフ表示2
※ボートレースの階級について
ボートレースの選手は階級が4つのランクに分かれており半年に1回更新されます。主に勝率(1着になる確率)、2連対率(2着以内になる確率)、3連対率(3着以内になる確率)と事故率や最低出走回数によってランク付けされます。勝率によって分けられるため、ランクの高い選手はランクの低い選手より良い成績になる可能性が高いと予想できます。実際のレースでもB1の選手は選択肢から除外する、1号艇がA1の選手の場合本命とするなど、階級が予想に使用されています。
(10)[DATA]、[SCALE]、[FILTER]を以下のように設定し、[RUN]をクリックします。
DATA:class/count
SCALE:is_higher_second
FILTER:class Equal A1
(11)円グラフ形式に変更します。
■ForePaaS操作画面(QUERIES)作成データ 円グラフ表示1
■ForePaaS操作画面(QUERIES)作成データ 円グラフ表示2
これでPart2の記事は終了となります。
次回のPart3では、まず材料となるデータの中で、本当に必要なデータはどれか、予想に悪影響を与える余計な材料はどれかを分析します。そして必要なデータのみを使って学習したモデルを構築し、実際の予想結果を見てみましょう。
最後に、JBSではForePaaSのデータ分析実装を継続的に支援するデータ分析ラボ for ForePaaSを提供しております。毎月ご契約いただいた時間を消費することで、要望をいただいた機能を実装および支援を行います。
ForePaaSを活用できるか悩んでいて導入を検討している、ForePaaSを導入したが継続的な機能実装に人手が足りないといった場合にぜひご検討ください。よろしくお願いいたします。
ForePaaSを活用できるか悩んでいて導入を検討している、ForePaaSを導入したが継続的な機能実装に人手が足りないといった場合にぜひご検討ください。よろしくお願いいたします。
こちらの関連記事も
合わせてお読みください