ForePaaSで公開データから機械学習モデルを構築する手順 ~Part3~


今回はボートレースの公開情報を収集し、着順予想のモデルを構築します。
※モデルのスコアを実用性のある精度にすることは本記事の対象としていません。
全体の記事
■ForePaaSへの (1)データ取り込み、(2)データ加工、(3)データ分析 に関する概要
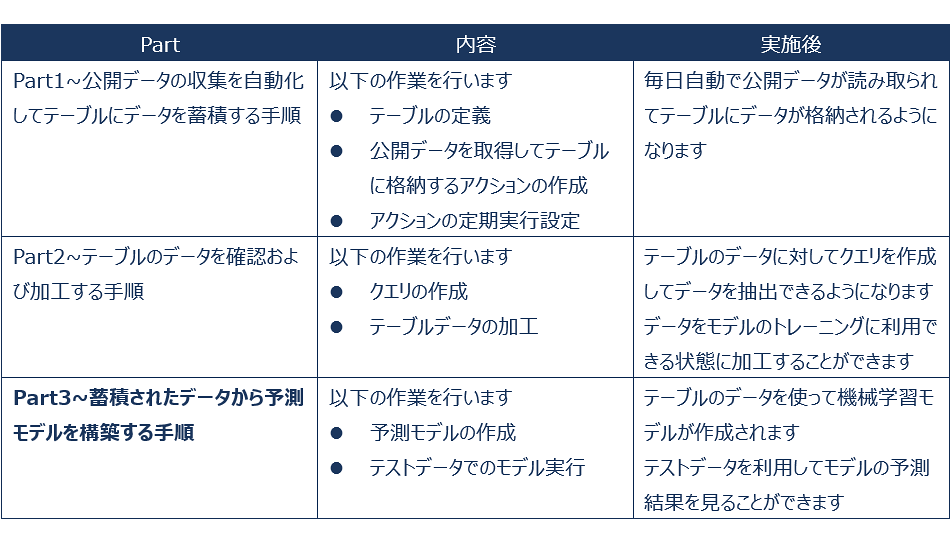
1. 今回のPartの概要
1.1. 分類モデルの作成
今回は機械学習を利用した分類モデルを作成し、ボートレースのデータから各選手が「2位以上になるか」を予測してみます。機械学習はデータを分析する方法の1つであり、データを元にコンピュータが学習し、インプットに対して予測や分類するための法則を発見するものです。
ForePaaSにはMachine Learning Managerという機能で簡単に機械学習を利用したモデルを作成することができます。また、この機能ではJupyter Notebookも利用することができ、pythonでデータの特徴を確認してモデル作成前の準備を行うこともできます。また、ForePaaSの他機能と同様にカスタマイズしたアルゴリズムを作成することや自社で既に持っているモデルをインポートすることもできます。
■Part3の範囲
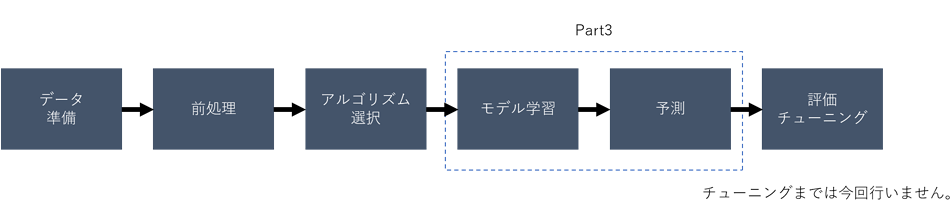
1.2. 手順概要
機械学習でコンピュータが学習して法則を見つけることができるように、計算に必要な情報をとりこむ必要があります。モデルは数値以外のデータを理解することができないため、使用したい文字列のデータは数値に変換して渡してあげる方が望ましいです。これをエンコーディングといいます。
今回はPart2で作成したAggregateアクションとテーブルのスキーマを変更し、文字列データとなっている「階級、レース場、支部」をエンコーディングします。
その後で、そのデータを使って機械学習モデルを作成します。新しいデータに対して予測した結果をForePaaSのテーブルに格納し、機械学習モデルの作成のステップは完了です。
■処理の流れイメージ
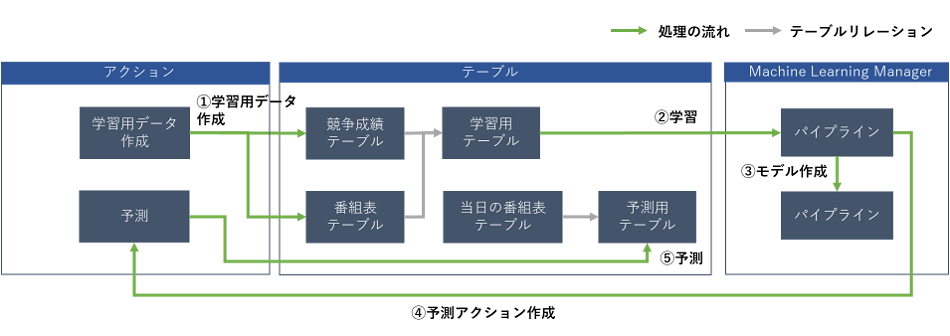
ForePaaSにはMachine Learning Managerという機能で簡単に機械学習を利用したモデルを作成することができます。また、この機能ではJupyter Notebookも利用することができ、pythonでデータの特徴を確認してモデル作成前の準備を行うこともできます。また、ForePaaSの他機能と同様にカスタマイズしたアルゴリズムを作成することや自社で既に持っているモデルをインポートすることもできます。
■Part3の範囲
今回はPart2で作成したAggregateアクションとテーブルのスキーマを変更し、文字列データとなっている「階級、レース場、支部」をエンコーディングします。
その後で、そのデータを使って機械学習モデルを作成します。新しいデータに対して予測した結果をForePaaSのテーブルに格納し、機械学習モデルの作成のステップは完了です。
■処理の流れイメージ
2. 手順
目次
2.1. Part2で作成したテーブルスキーマとAggregateアクションを変更する
まずは前回作成したテーブルのスキーマを変更して、「階級、レース場、支部」の型を数値に変換します。
(1)[DATA MANAGER]にアクセスします。
(2)[TABLES]にアクセスし、見やすいように右上の表示形式でリスト形式を選択します。
■ForePaaS操作画面(TABLES)
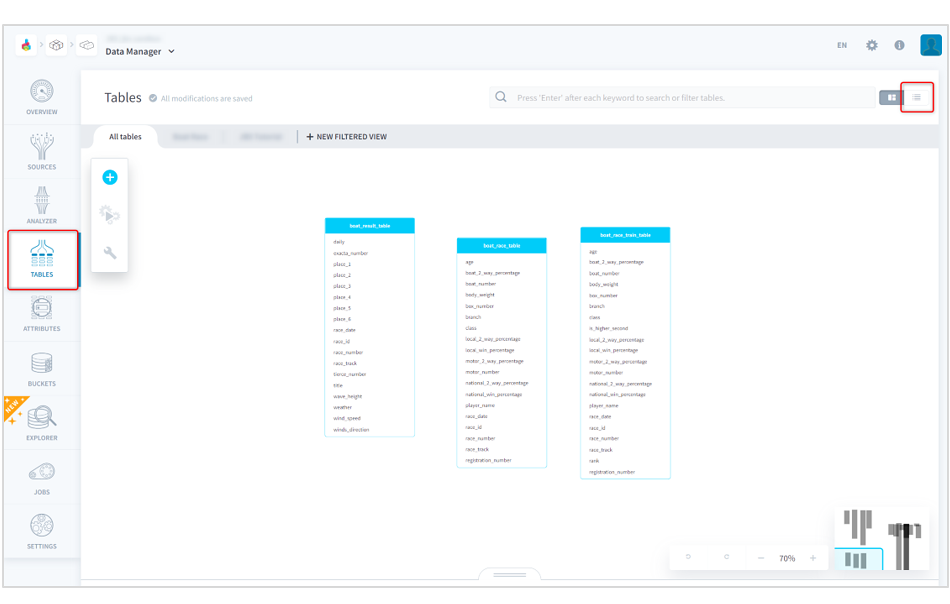 (3)前回学習用テーブルとして作成した「boat_race_train_table(前回つけた任意の名前)」の右にある[Infos]をクリックして、テーブル構造を表示します。
(3)前回学習用テーブルとして作成した「boat_race_train_table(前回つけた任意の名前)」の右にある[Infos]をクリックして、テーブル構造を表示します。
■ForePaaS操作画面(TABLES)テーブル構造を表示
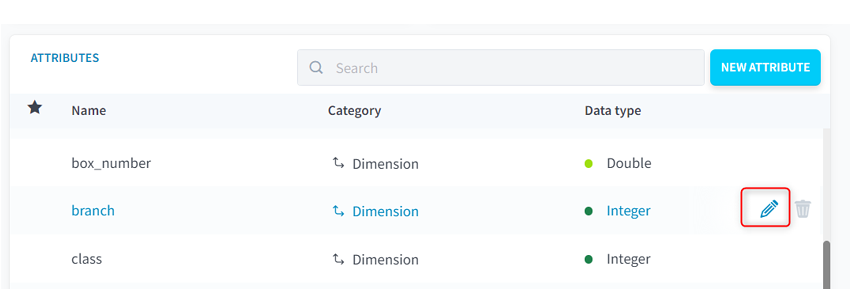
 (4)テーブルの中から階級、レース場、支部の項目を探して、[編集]をクリックします。
(4)テーブルの中から階級、レース場、支部の項目を探して、[編集]をクリックします。
■ForePaaS操作画面(TABLES)スキーマ変更1
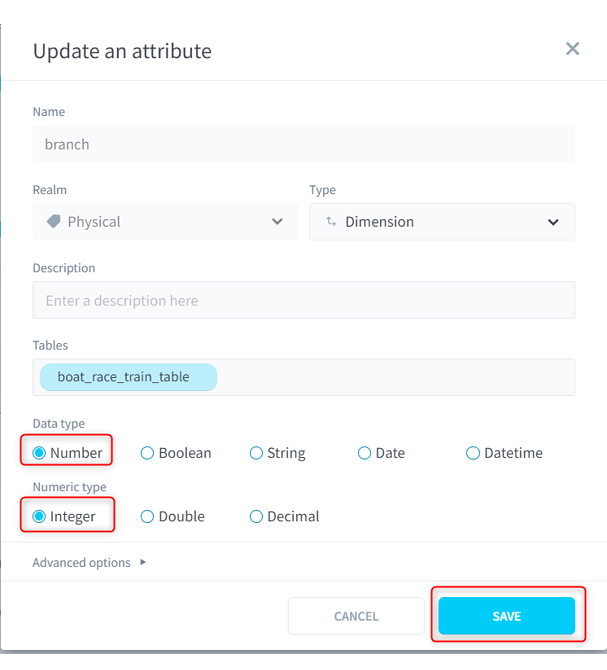
 (5)Data typeを「String(文字列)」から「Number(数値)」に変更し、Numeric typeを「Integer(整数)」に変更して[SAVE]をクリックします。これで、これまで例えば「びわこ」とデータ格納できていたところに整数しか入れられなくなります。
(5)Data typeを「String(文字列)」から「Number(数値)」に変更し、Numeric typeを「Integer(整数)」に変更して[SAVE]をクリックします。これで、これまで例えば「びわこ」とデータ格納できていたところに整数しか入れられなくなります。
■ForePaaS操作画面(TABLES)スキーマ変更2
 (6) 階級、レース場、支部の項目に対して(4)~(5)の手順を行います。
(6) 階級、レース場、支部の項目に対して(4)~(5)の手順を行います。
(7)テーブルの右にある[Build]をクリックします。
■ForePaaS操作画面(TABLES)スキーマ変更3
 これでテーブルのスキーマ変更は完了です。
これでテーブルのスキーマ変更は完了です。
次にAggregateアクションを修正して、先ほど修正したテーブルの型に合わせて文字列から整数に置き換えていきます。
(1)[DATA PROCESSING ENGINE]にアクセスします。
(2)[ACTIONS]にアクセスし、前回作成したAggregateアクションの[編集]をクリックします。
■ForePaaS操作画面(ACTIONS)Aggregateアクションの修正
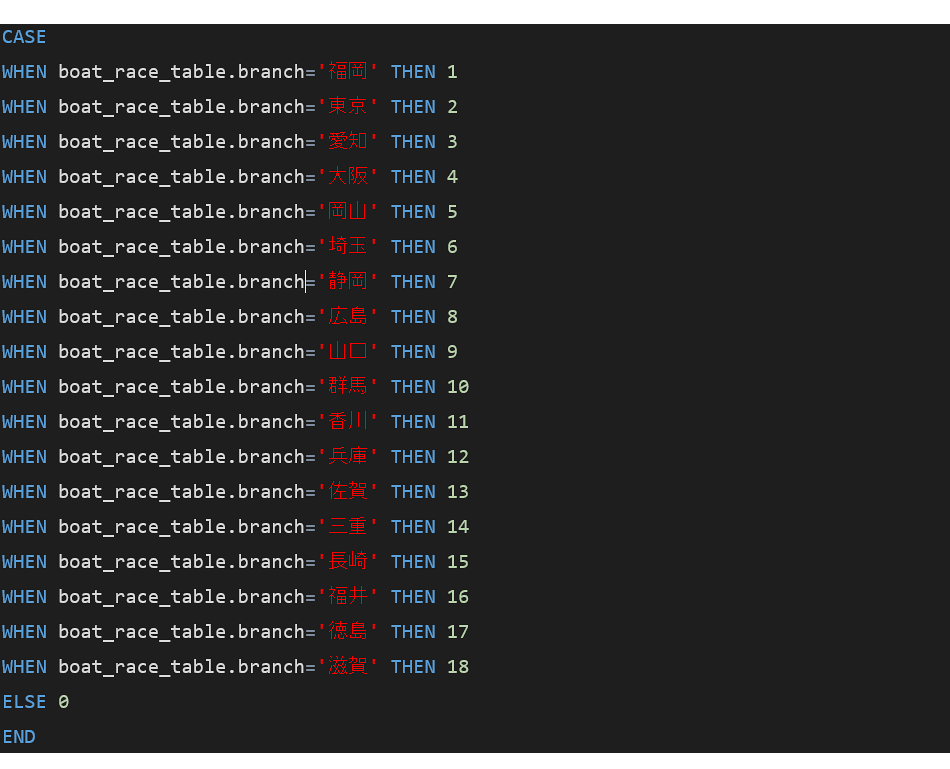
 (3)「class、race_track、branch」の[map]を[sql]に変更し、それぞれ以下のコードを記載します。
(3)「class、race_track、branch」の[map]を[sql]に変更し、それぞれ以下のコードを記載します。
■class

■race_track1
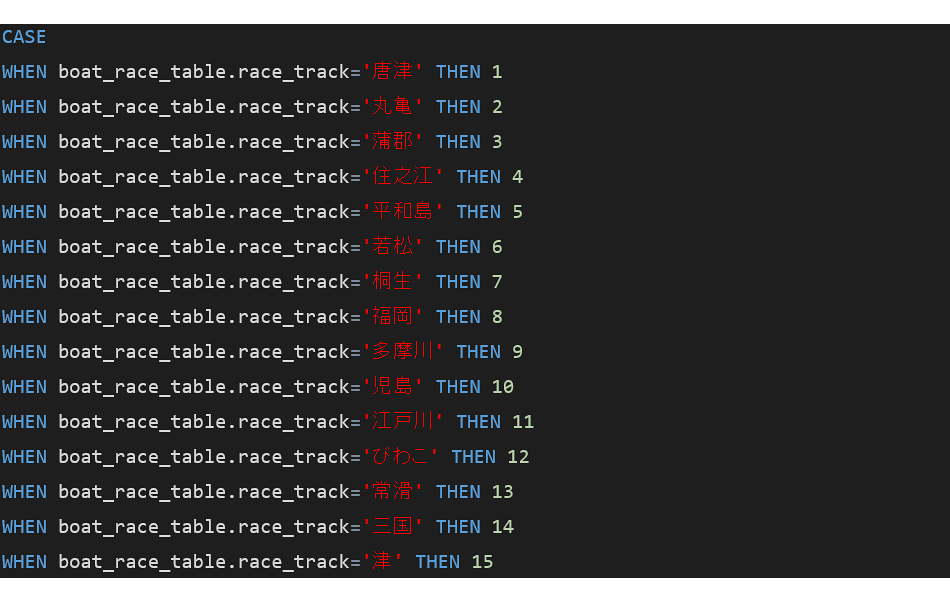
■race_track2
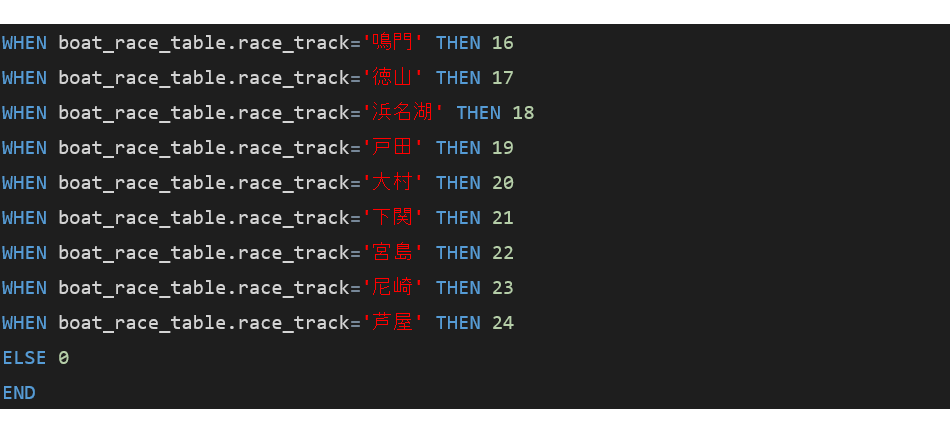
■branch
 (4)右上のRUNボタンをクリックしてActionを実行します。これでAggregateアクションの修正は完了です。
(4)右上のRUNボタンをクリックしてActionを実行します。これでAggregateアクションの修正は完了です。
テーブルスキーマ変更もアクション修正もGUIベースで簡単に作業できました。アクションについてはSQL文を学ぶともっとデータ加工の幅が広がりそうです。
エンコーディングについて
今回は各値に対してラベルを割り当てるラベルエンコーディングをしています。
この場合、数値の大小に意味はない(classの場合1(A1)+2(A2) = 3(B1)という意味にならない)ため、モデルの計算精度に影響する可能性があります。分析手法に合わせてワンホットエンコーディングなど他のエンコーディング手法の検討をしてください。
2.2. 機械学習モデルを作成する
先ほど新たにデータが投入されたboat_race_train_tableを使用して機械学習モデルを作成します。一般的なアルゴリズムを使用する場合はForePaaSでは簡単にモデルを作成することができます。ForePaaSのMACHINE LEARNING MANAGERにはPIPELINEという機能が用意されており、ステップを通して機械学習モデルを作成していくことができるようになっています。
これまで作成してきたアクションを使って2020年1月から2023年2月までのデータをForePaaSのテーブルに格納しています。これを学習データとしてモデルを作成していきます。
(1)[MACHINE LEARNING MANAGER]にアクセスします。
■ForePaaS操作画面(MACHINE LEARNING MANAGER)モデル作成1
 (2)[PIPELINES]にアクセスし、[NEW PIPELINE]をクリックして、PIPELINEを作成します。
(2)[PIPELINES]にアクセスし、[NEW PIPELINE]をクリックして、PIPELINEを作成します。
■ForePaaS操作画面(PIPELINES)モデル作成2
 (3)名前に機械学習の処理を行う任意の名前を入力し、テーブルの値を用いて予測するために[DATASET]をクリックします。この最初のステップではどのテーブルを使って学習するのか、テーブルの中のどの値を予測したいのか、予測するためのインプットにどの値を使用するのかなどを設定できます。
(3)名前に機械学習の処理を行う任意の名前を入力し、テーブルの値を用いて予測するために[DATASET]をクリックします。この最初のステップではどのテーブルを使って学習するのか、テーブルの中のどの値を予測したいのか、予測するためのインプットにどの値を使用するのかなどを設定できます。
■ForePaaS操作画面(PIPELINES)モデル作成3
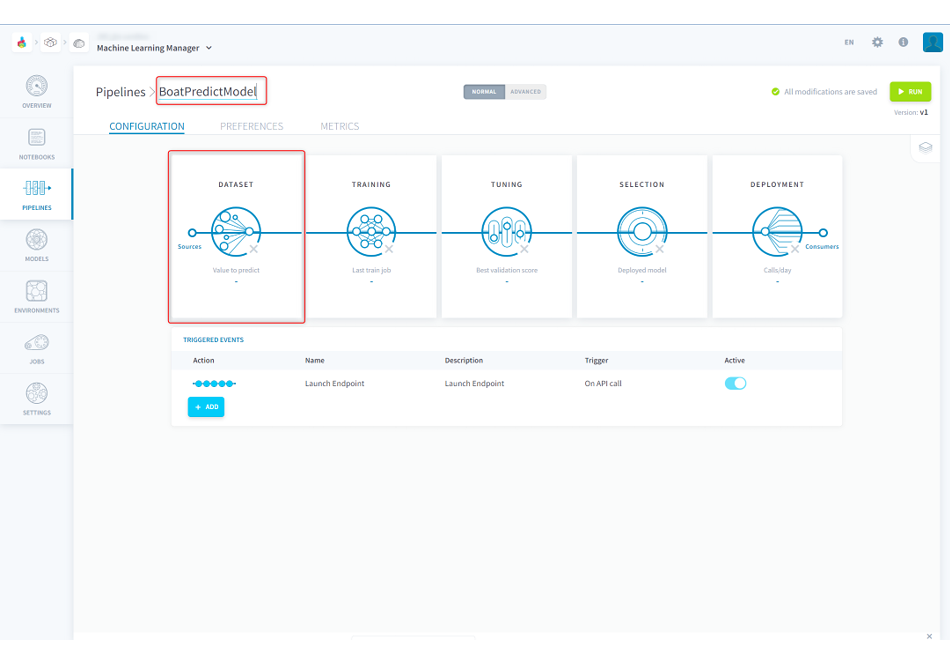
■パイプラインのDataSet
 ①テーブル選択
①テーブル選択
学習する対象のテーブルをForePaaS内のテーブル一覧から選択します。
②バリデーション設定
選択されたテーブルのデータを、ここで設定された割合で学習用データとテスト用データとして分割し、学習用データでモデルを作成してテストデータでモデルの精度を検証します。
③目的変数と説明変数の選択
予測したい目的変数の設定と、予測に使用する説明変数を設定します。
目的変数と説明変数とは・・・
●目的変数:使用するデータのうち予測したい項目。今回の場合は「2位以上になるか」のis_higher_secondが目的変数となる。
●説明変数:目的変数を予測するために使用する項目。今回の場合は2以上になるかという予測のために、艇番や全国勝率などの情報を利用する。これらが説明変数となる。
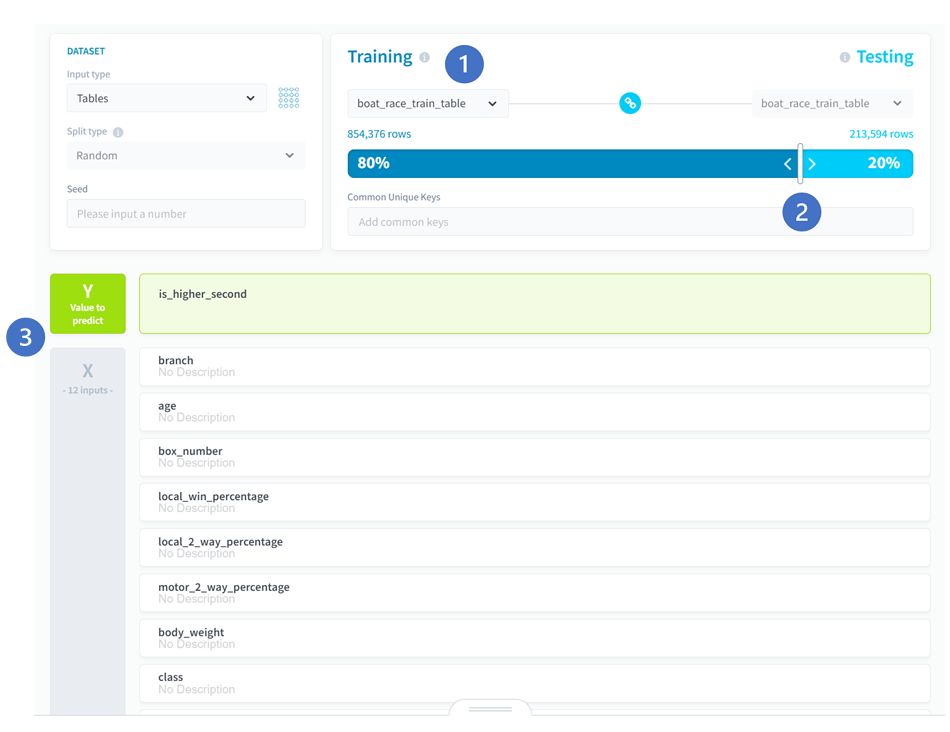
(4)Choose a valueで[boat_race_train_table]を選択します。
■ForePaaS操作画面 モデル作成4
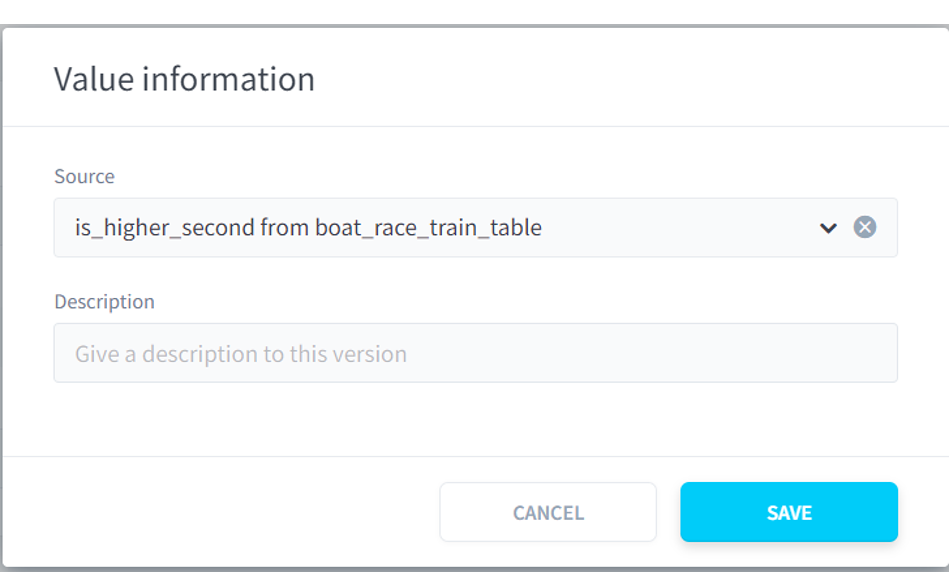
 (5)Yには予測したい値を設定するため、[is_higher_second]を選択します。
(5)Yには予測したい値を設定するため、[is_higher_second]を選択します。
■ForePaaS操作画面 モデル作成5
 (6)Xには予測するために使用するインプット情報を選択するため、テーブルに格納された列として以下の値を選択し、[ADD 12 SOURCES]をクリックします。
(6)Xには予測するために使用するインプット情報を選択するため、テーブルに格納された列として以下の値を選択し、[ADD 12 SOURCES]をクリックします。
branch,age,box_number,loacal_win_percentage.local_2_way_percentage,motor_2_way_percentage,body_weight,class,race_track,national_win_percentage,national_2_way_percentage,boat_2_way_percentage
■ForePaaS操作画面 モデル作成6
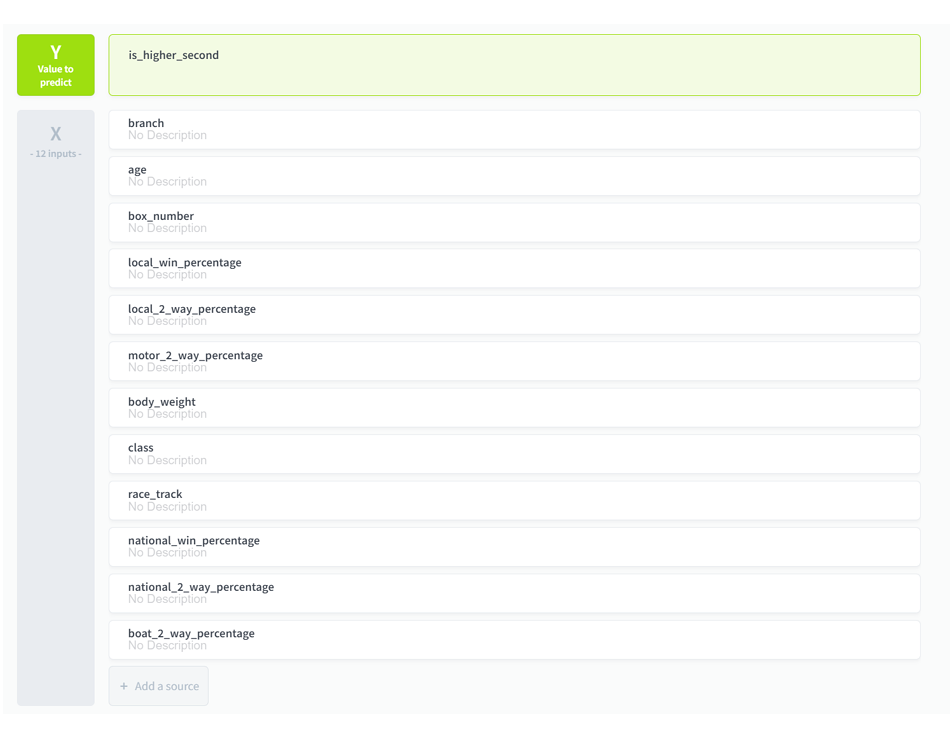 選手名や日付は順位に影響しないため選択しません。
選手名や日付は順位に影響しないため選択しません。
(7)機械学習のアルゴリズムを選択するために[Training]に移動し、[STANDARD ESTIMATOR]>[Random Forest]を選択して[SELECT]をクリックします。ForePaaSではPythonでコードを書いてカスタムのアルゴリズムを実行することもできます。今回は分類に利用できそうなランダムフォレストというアルゴリズムを使用してみます。
■ForePaaS操作画面 モデル作成7
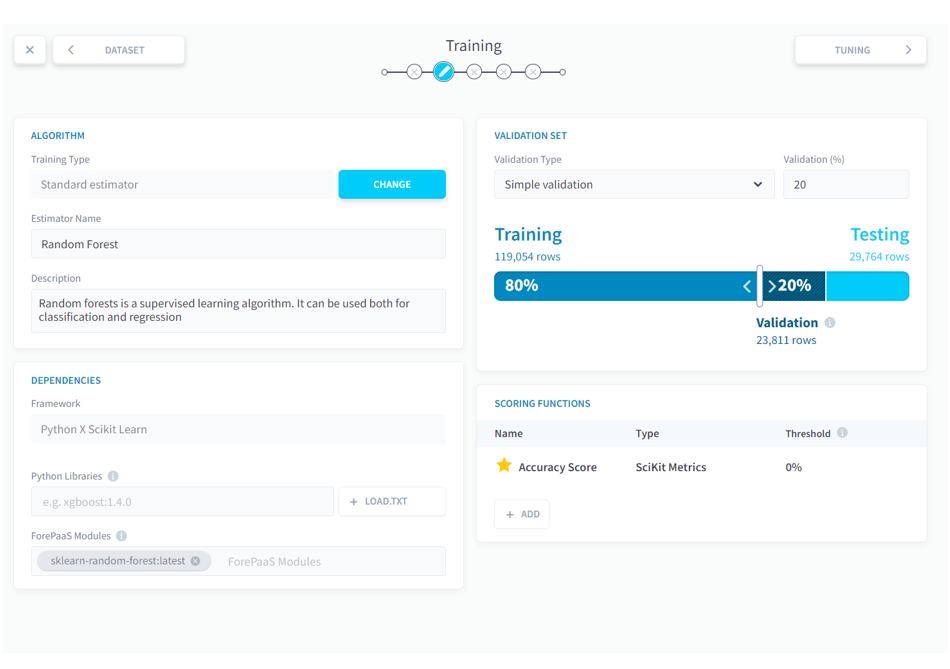
※ランダムフォレスト
決定木と呼ばれる、階層構造的に特徴量を二者択一の条件によって分岐させていき、それぞれの分岐によって最終的に予測したい項目の結果の割合がどうなるか分析する手法があります。ランダムフォレストは説明変数の中からランダムに特徴量を取り出し決定木を作成し、それを多数作成して組み合わせて多数決や平均で最終的な予測をするアルゴリズムです。
ランダムフォレストは調整すべきパラメータが少ない、説明変数を厳しく選択する必要がないなど、使いやすさがある一方で、他のアルゴリズムと比較して平均的な精度が高いという理由から今回選択しています。
(8)Tuningをクリックします。
ここでは選択したアルゴリズムごとに使用されるパラメータの値を変更することで、モデルの精度をチューニングすることができます。画面にはランダムフォレストで設定できるパラメータが表示されています。項目が12個用意されていますが、今回はランダムフォレストのパラメータの中でもよくチューニングに使用される「max_depth」と「n_estimators」の値を変更してみます。
●max_depth:多数作成する決定木の階層の深さを設定するものです。
階層が深いほど複雑な条件を使った分析をしてくれますが、学習データに対して過剰にフィットしてしまい、新しいデータの予測には逆に使えなくなってしまう可能性があります。デフォルトはNoneで階層をどこまでも深くするような設定となっています。
●n_estimators:多数作成する決定木の数を設定するものです。
これは決定木がたくさんあればあるほど精度は高くなりますが、計算時間がかかるようになります。デフォルトは10となっています。
今回は、事前に何回かパラメータを試してみて結果の良かった以下の設定値を採用することにします。
max_depth: 10
n_estimators: 50
最適な設定値を細かく確認したい場合は、各設定値の組み合わせでモデルの精度をすべて確認してベストなパラメータを出力するグリッドサーチなどの検討をしてみてください。
■ForePaaS操作画面 モデル作成8
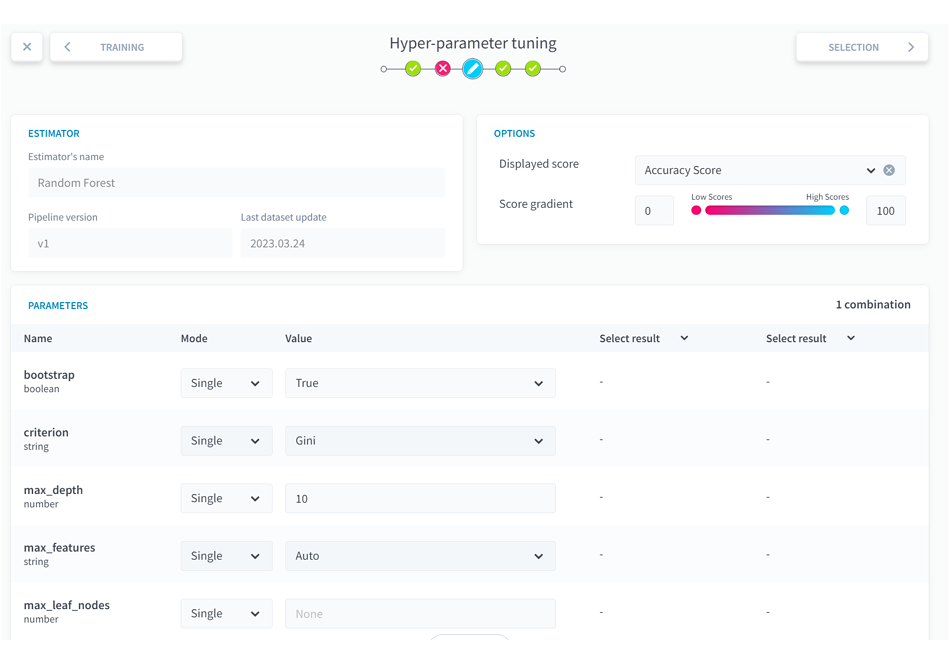 (9)ここまできたら右上の[RUN]をクリックし、実行ボタンをクリックします。
(9)ここまできたら右上の[RUN]をクリックし、実行ボタンをクリックします。
■ForePaaS操作画面 モデル作成9
 (10)モデルの学習が完了すると、ログには以下のように正答率が70%程度だという結果が表示されます。
(10)モデルの学習が完了すると、ログには以下のように正答率が70%程度だという結果が表示されます。
■ForePaaS操作画面 モデル学習結果
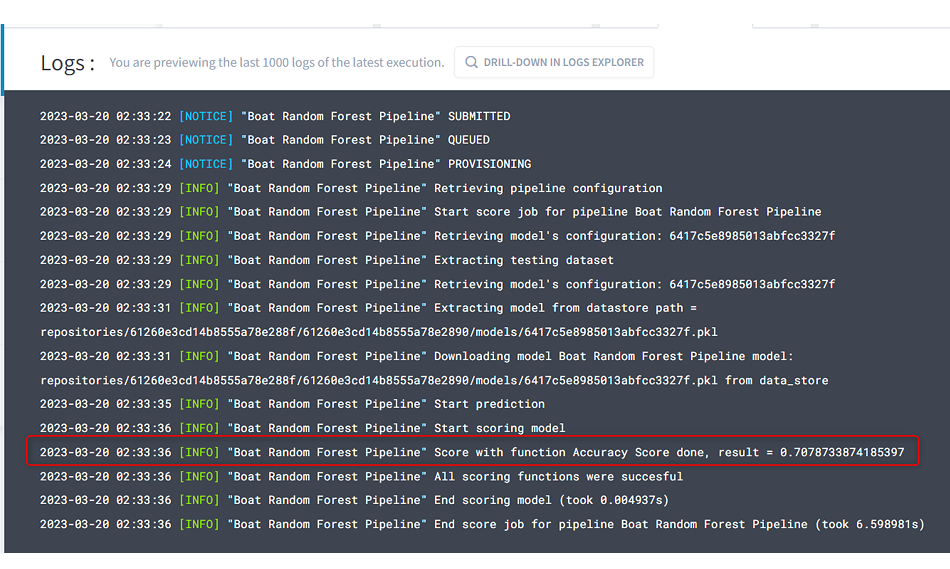 モデル作成についてもGUIベースで完結できました。
モデル作成についてもGUIベースで完結できました。
選択したアルゴリズムを使ってモデルに学習させることができ、テストデータを使用した正答率についても確認することができています。既に使用しているモデルがあってもすぐにインポートすることができるため、ForePaaS上でのモデル作成は非常に簡単でした。
2.3. 予測結果をテーブルに格納する
では、実際に予測した結果をテーブルに格納します。
今回モデルで使用した説明変数を持つテーブルを用意する必要があるため、boat_race_train_tableを複製したテーブルを作成し、さらに同様のAggregateアクションを作成します。
■Aggregateアクション作成範囲
 (1)[DATA MANAGER]>[TABLES]にアクセスします。
(1)[DATA MANAGER]>[TABLES]にアクセスします。
(2)「boat_race_table」と「boat_race_train_table」を複製します。名前を任意で付けてください。
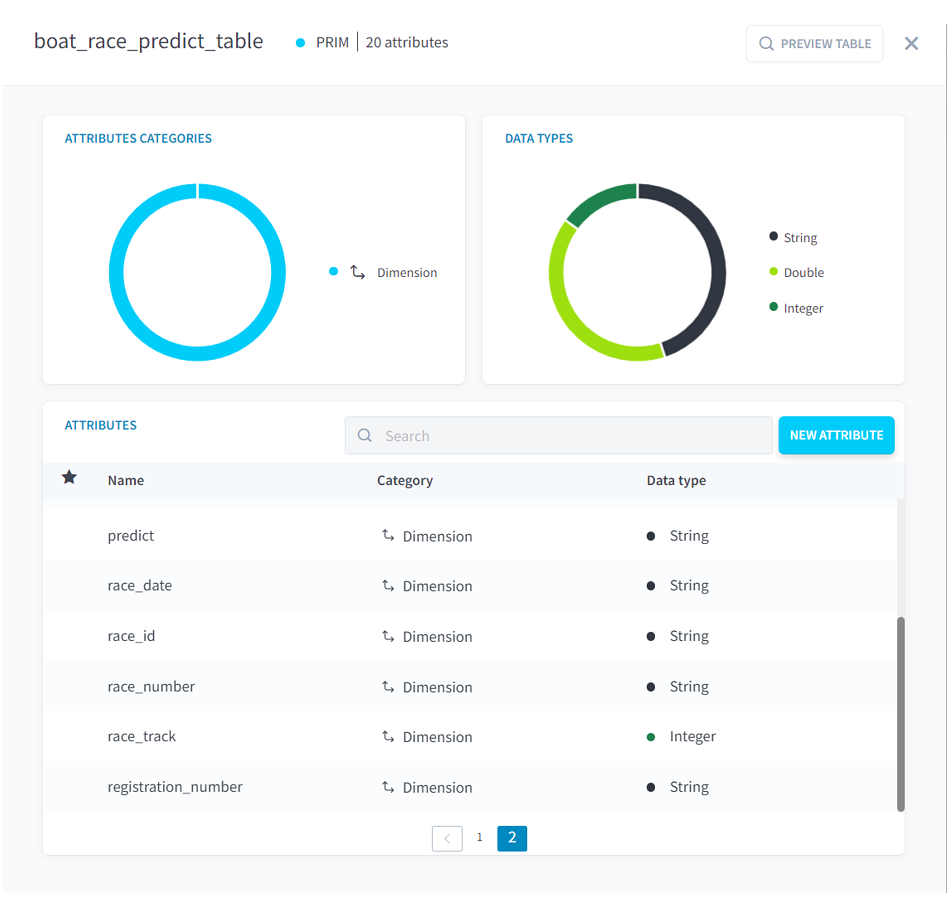
(3)「boat_race_train_table」を複製したテーブルのInfosをクリックします。[is_higher_second]を削除し、[predict]という文字列型の列を追加して、ビルドします。
■ForePaaS操作画面(TABLES)Aggregateアクション作成1
 (4)[DATA PROCESSING ENGINE]>[ACTIONS]にアクセスし、Part1で作成した[Boat Player Load]アクションを複製し、コード内のTABLENAMEを複製したテーブル名に修正します。
(4)[DATA PROCESSING ENGINE]>[ACTIONS]にアクセスし、Part1で作成した[Boat Player Load]アクションを複製し、コード内のTABLENAMEを複製したテーブル名に修正します。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成2
 (5)Part2で作成したAggregateアクションを複製します。
(5)Part2で作成したAggregateアクションを複製します。
(6)ソースは「boat_race_table」を複製したテーブルにして、宛先に「boat_race_train_table」を複製したテーブルを指定します。Predictは予測アクションで値を入れるため、今の段階では削除します。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成3
 (7)[MACHINE LEARNING MANAGER]にアクセスして先ほど作成したパイプラインの編集を開きます。
(7)[MACHINE LEARNING MANAGER]にアクセスして先ほど作成したパイプラインの編集を開きます。
(8)[DEPLOYMENT]というステップに移動し、Deployment Best Modelをクリックします。
(9)[CONSUMERS]の[ADD]をクリックし、任意の名前をつけ、Typeをテーブルに変更し、「boat_race_train_table」を複製したテーブルを選択します。
■ForePaaS操作画面(MACHINE LEARNING MANAGER)
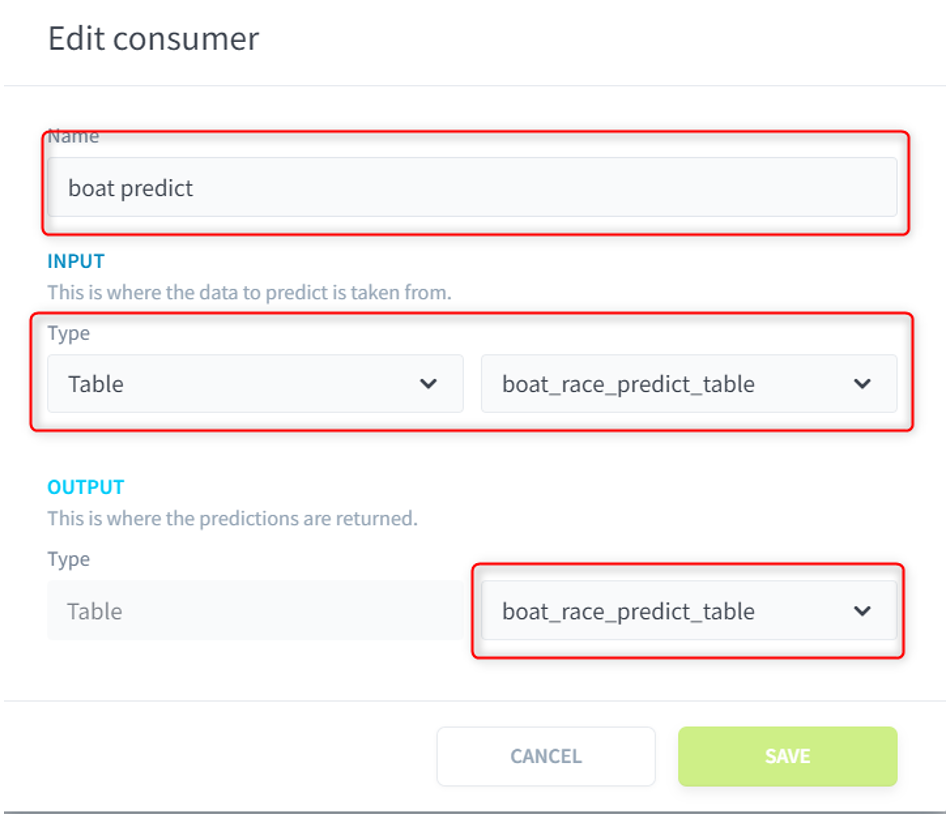 これにより、選択されたテーブルに対してモデルで予測を行って結果を格納するアクションが作成されました。
これにより、選択されたテーブルに対してモデルで予測を行って結果を格納するアクションが作成されました。
(10)[DATA PROCESSING ENGINE]>[ACTIONS]にアクセスし、[Machine Learning]タブを開くと、先ほど作成された予測アクションがあるため、編集をクリックします。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成5
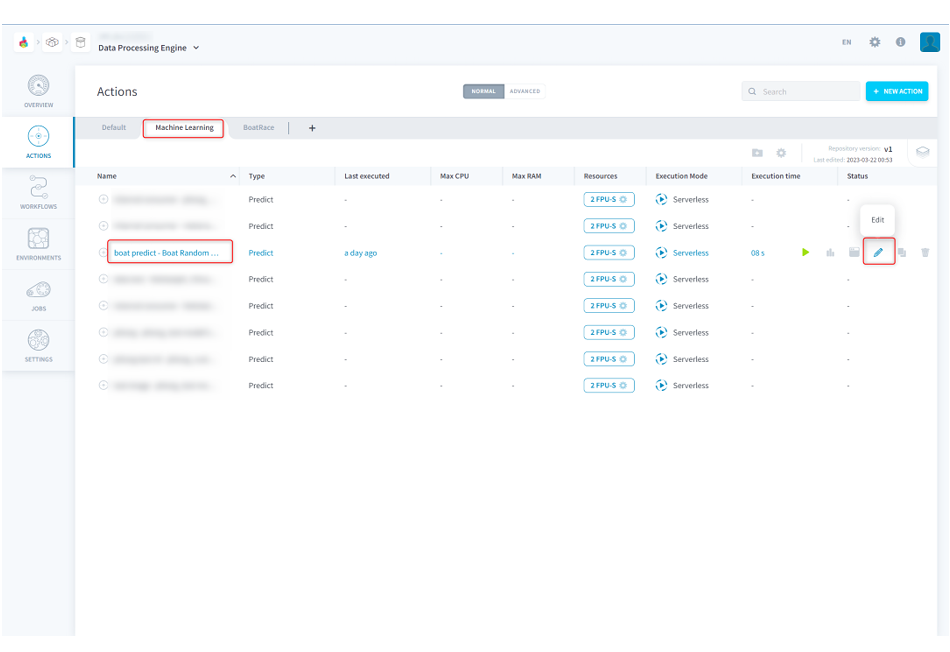 (11)[DIRECT LOADING]を有効にし、登録番号とレースIDをキーに設定します。これによって、予測した結果を該当の行のpredict列に格納します。
(11)[DIRECT LOADING]を有効にし、登録番号とレースIDをキーに設定します。これによって、予測した結果を該当の行のpredict列に格納します。
(12)右側のSelect an attributeで[predict]を選択し、[RUN]をクリックします。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成6
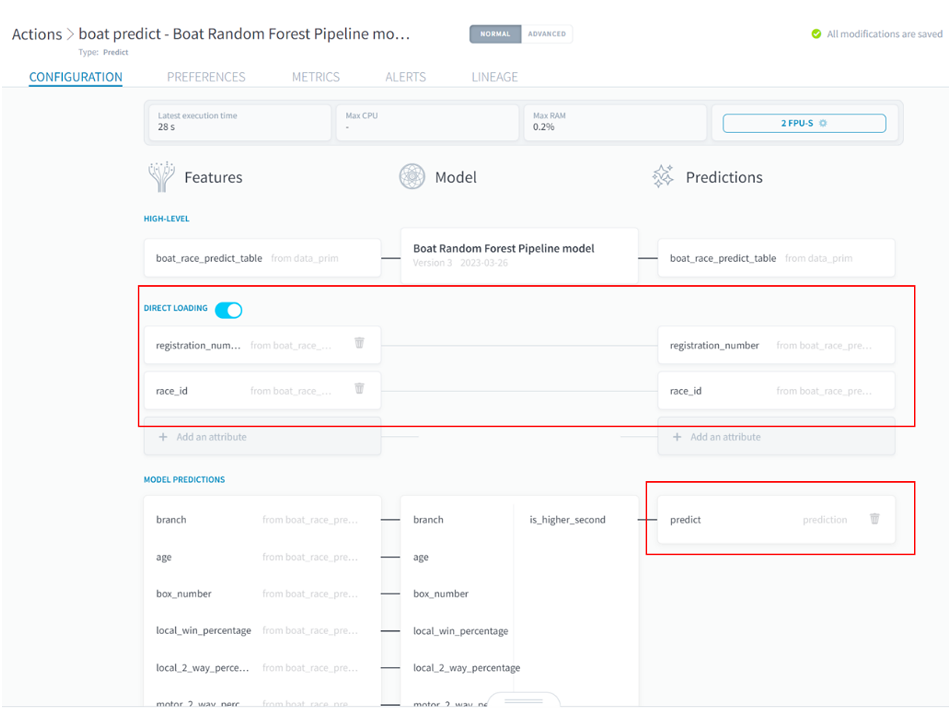 これで、データに対してモデルが予測した結果がテーブルに格納されました!Analytics Managerで見てみます。
これで、データに対してモデルが予測した結果がテーブルに格納されました!Analytics Managerで見てみます。
全体表示してみると、predict列に1か0の値が入っています!予測結果が格納されていますね。
■ForePaaS操作画面(Queries)予測結果1
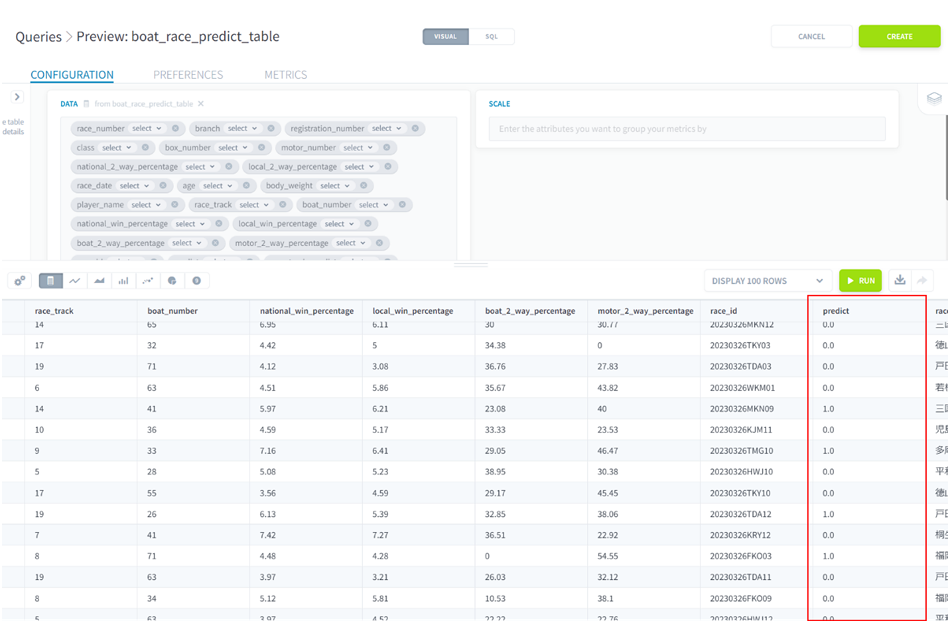 予想結果0と1の数はそれぞれ以下のようになっています。2着以上にならないと予想された選手が全体の78%、2着以上であると予想された選手が全体の22%という結果でした。毎レース6選手が出場してそのうち2着以上になる選手の予想をするため、2着以上であると予想される選手は33%程度になる想定でしたが、大きく差があるわけではないため問題ないと判断します。
予想結果0と1の数はそれぞれ以下のようになっています。2着以上にならないと予想された選手が全体の78%、2着以上であると予想された選手が全体の22%という結果でした。毎レース6選手が出場してそのうち2着以上になる選手の予想をするため、2着以上であると予想される選手は33%程度になる想定でしたが、大きく差があるわけではないため問題ないと判断します。
■ForePaaS操作画面(Queries)予測結果2
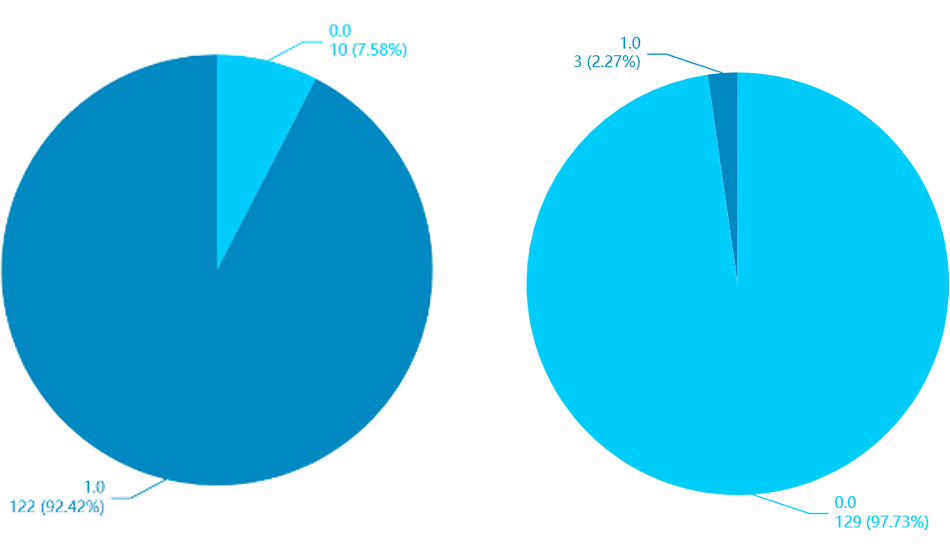
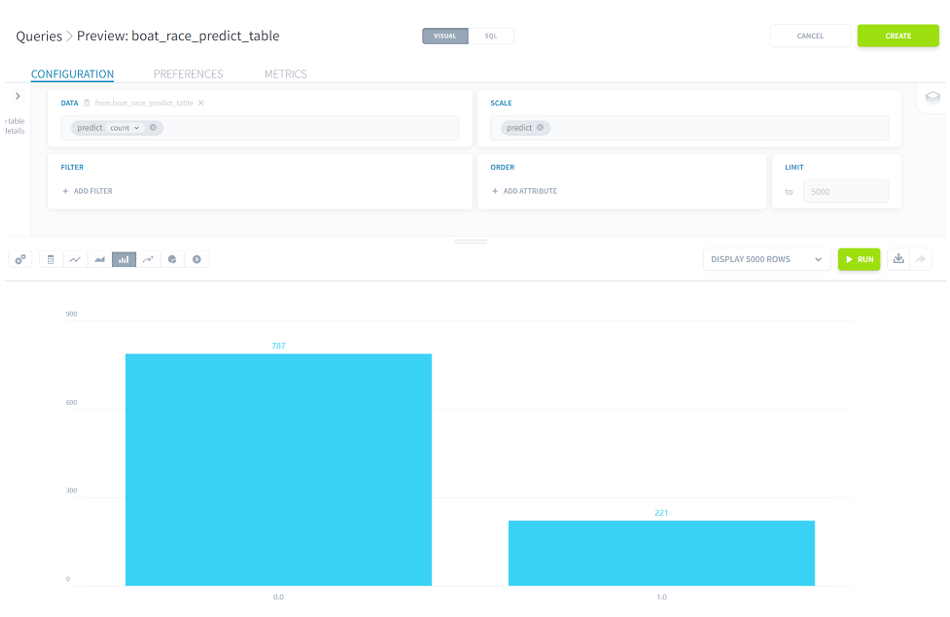 ちなみに艇番が1の場合と5の場合の予測結果は以下のようになっています。(6はすべて予測結果が0でした。少し素直すぎる予測な気がします。)
ちなみに艇番が1の場合と5の場合の予測結果は以下のようになっています。(6はすべて予測結果が0でした。少し素直すぎる予測な気がします。)
ボートレースの基礎であるインコースが強い傾向などが反映された予測はしてくれていそうですね。
■艇番が1と5の予測結果
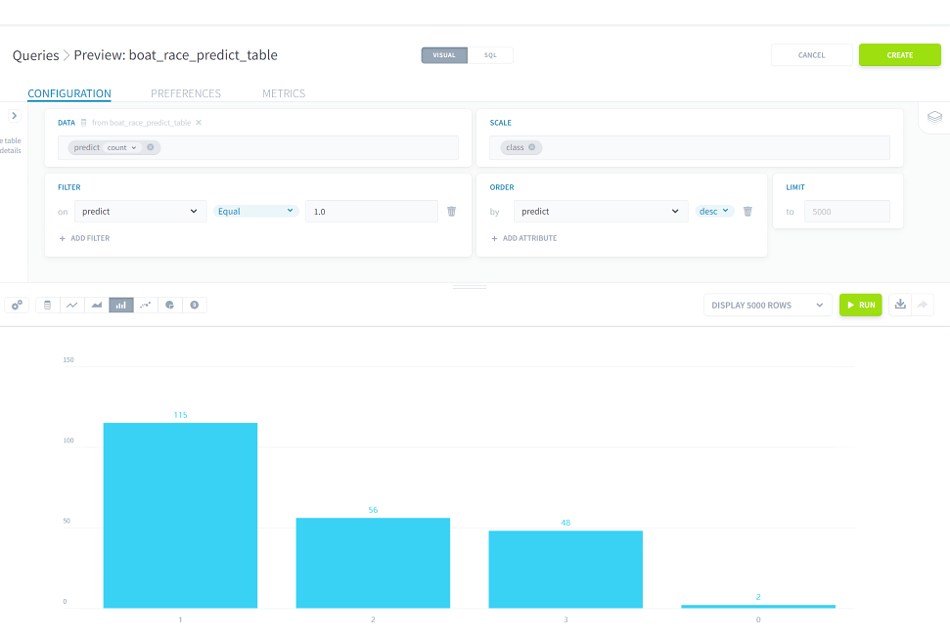
 階級ごとの予測結果1(2着以上になる)の数は以下のようになっていました。
階級ごとの予測結果1(2着以上になる)の数は以下のようになっていました。
(1=A1、2=A2、3=B1、0=B2)
艇番だけでなく階級による傾向もしっかり学習していそうです。階級がB2の場合は2選手のみで極端に少ない気もします。
■ForePaaS操作画面(Queries)予測結果3
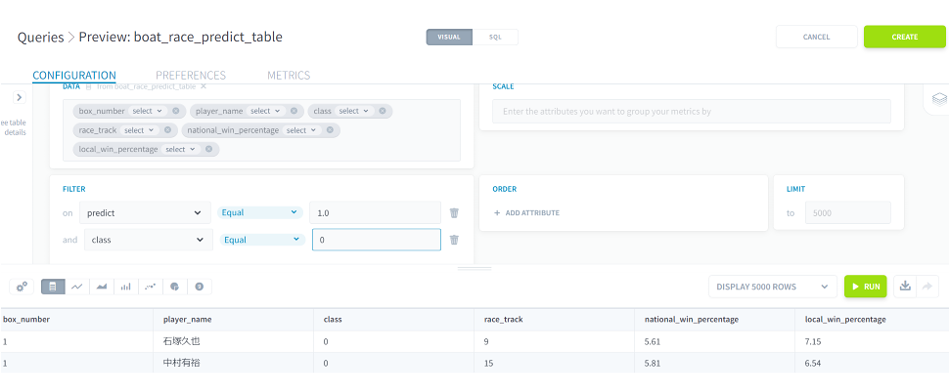
 B2の2選手の情報を見るとやはり艇番が1でした。かつ、そのレース場での勝率(local_win_percentage)がそれなりに高かったので、そういった要素が要因となっていそうです。でもやはり艇番の影響を強く受けていそうな気がします。
B2の2選手の情報を見るとやはり艇番が1でした。かつ、そのレース場での勝率(local_win_percentage)がそれなりに高かったので、そういった要素が要因となっていそうです。でもやはり艇番の影響を強く受けていそうな気がします。
■ForePaaS操作画面(Queries)予測結果4
 少し予測結果を見てみましたが、いかがでしょうか。正答率はこれだけでは高いかわかりませんが、実際のデータに対してモデルを使った予測がForePaaSでできました。モデルの作成とモデルでの分類はほとんどコードを書かずに作成できています。
少し予測結果を見てみましたが、いかがでしょうか。正答率はこれだけでは高いかわかりませんが、実際のデータに対してモデルを使った予測がForePaaSでできました。モデルの作成とモデルでの分類はほとんどコードを書かずに作成できています。
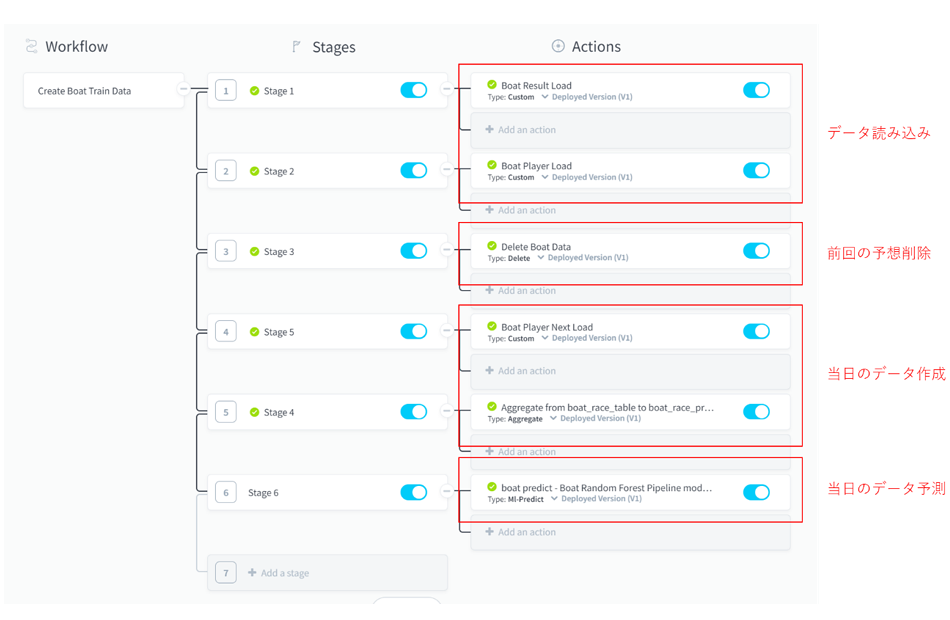
モデルの予測は先ほど見た通りForePaaSのアクションとして作成されるので、データの取り込みと合わせてワークフローに組み込むことで、定期的に自動実行させることができます。
■ワークフロー例
2.4. まとめ
Part1~3にかけてForePaaSで機械学習モデルを作成する流れを見てきました。
データを収集・加工を自動化し、データを探索、データで学習したモデルを作成して予測という流れを全部ForePaaS上でできました。今回は少し複雑なテキストデータが元データだったため、pythonコードで書いている部分はありますが、CSVやDBなどのデータであればもっと簡単に読み込みからモデル作成までできると思います。
みなさんも、ぜひForePaaSでAIでの予測や分類にチャレンジしてみてはいかがでしょうか!次はAzureやMicrosoft365のデータを使った分析をしてみたいなと思っています。
最後に、JBSではForePaaSのデータ分析実装を継続的に支援するデータ分析ラボ for ForePaaSを提供しております。毎月ご契約いただいた時間を消費することで、要望をいただいた機能を実装および支援を行います。
ForePaaSを活用できるか悩んでいて導入を検討している、ForePaaSを導入したが継続的な機能実装に人手が足りないといった場合にぜひご検討ください。よろしくお願いいたします。
(1)[DATA MANAGER]にアクセスします。
(2)[TABLES]にアクセスし、見やすいように右上の表示形式でリスト形式を選択します。
■ForePaaS操作画面(TABLES)
■ForePaaS操作画面(TABLES)テーブル構造を表示
■ForePaaS操作画面(TABLES)スキーマ変更1
■ForePaaS操作画面(TABLES)スキーマ変更2
(7)テーブルの右にある[Build]をクリックします。
■ForePaaS操作画面(TABLES)スキーマ変更3
次にAggregateアクションを修正して、先ほど修正したテーブルの型に合わせて文字列から整数に置き換えていきます。
(1)[DATA PROCESSING ENGINE]にアクセスします。
(2)[ACTIONS]にアクセスし、前回作成したAggregateアクションの[編集]をクリックします。
■ForePaaS操作画面(ACTIONS)Aggregateアクションの修正
■class
■race_track1
■race_track2
■branch
テーブルスキーマ変更もアクション修正もGUIベースで簡単に作業できました。アクションについてはSQL文を学ぶともっとデータ加工の幅が広がりそうです。
この場合、数値の大小に意味はない(classの場合1(A1)+2(A2) = 3(B1)という意味にならない)ため、モデルの計算精度に影響する可能性があります。分析手法に合わせてワンホットエンコーディングなど他のエンコーディング手法の検討をしてください。
これまで作成してきたアクションを使って2020年1月から2023年2月までのデータをForePaaSのテーブルに格納しています。これを学習データとしてモデルを作成していきます。
(1)[MACHINE LEARNING MANAGER]にアクセスします。
■ForePaaS操作画面(MACHINE LEARNING MANAGER)モデル作成1
■ForePaaS操作画面(PIPELINES)モデル作成2
■ForePaaS操作画面(PIPELINES)モデル作成3
■パイプラインのDataSet
学習する対象のテーブルをForePaaS内のテーブル一覧から選択します。
②バリデーション設定
選択されたテーブルのデータを、ここで設定された割合で学習用データとテスト用データとして分割し、学習用データでモデルを作成してテストデータでモデルの精度を検証します。
③目的変数と説明変数の選択
予測したい目的変数の設定と、予測に使用する説明変数を設定します。
●説明変数:目的変数を予測するために使用する項目。今回の場合は2以上になるかという予測のために、艇番や全国勝率などの情報を利用する。これらが説明変数となる。
(4)Choose a valueで[boat_race_train_table]を選択します。
■ForePaaS操作画面 モデル作成4
■ForePaaS操作画面 モデル作成5
branch,age,box_number,loacal_win_percentage.local_2_way_percentage,motor_2_way_percentage,body_weight,class,race_track,national_win_percentage,national_2_way_percentage,boat_2_way_percentage
■ForePaaS操作画面 モデル作成6
(7)機械学習のアルゴリズムを選択するために[Training]に移動し、[STANDARD ESTIMATOR]>[Random Forest]を選択して[SELECT]をクリックします。ForePaaSではPythonでコードを書いてカスタムのアルゴリズムを実行することもできます。今回は分類に利用できそうなランダムフォレストというアルゴリズムを使用してみます。
■ForePaaS操作画面 モデル作成7
ランダムフォレストは調整すべきパラメータが少ない、説明変数を厳しく選択する必要がないなど、使いやすさがある一方で、他のアルゴリズムと比較して平均的な精度が高いという理由から今回選択しています。
(8)Tuningをクリックします。
ここでは選択したアルゴリズムごとに使用されるパラメータの値を変更することで、モデルの精度をチューニングすることができます。画面にはランダムフォレストで設定できるパラメータが表示されています。項目が12個用意されていますが、今回はランダムフォレストのパラメータの中でもよくチューニングに使用される「max_depth」と「n_estimators」の値を変更してみます。
●max_depth:多数作成する決定木の階層の深さを設定するものです。
階層が深いほど複雑な条件を使った分析をしてくれますが、学習データに対して過剰にフィットしてしまい、新しいデータの予測には逆に使えなくなってしまう可能性があります。デフォルトはNoneで階層をどこまでも深くするような設定となっています。
●n_estimators:多数作成する決定木の数を設定するものです。
これは決定木がたくさんあればあるほど精度は高くなりますが、計算時間がかかるようになります。デフォルトは10となっています。
今回は、事前に何回かパラメータを試してみて結果の良かった以下の設定値を採用することにします。
max_depth: 10
n_estimators: 50
最適な設定値を細かく確認したい場合は、各設定値の組み合わせでモデルの精度をすべて確認してベストなパラメータを出力するグリッドサーチなどの検討をしてみてください。
■ForePaaS操作画面 モデル作成8
■ForePaaS操作画面 モデル作成9
■ForePaaS操作画面 モデル学習結果
選択したアルゴリズムを使ってモデルに学習させることができ、テストデータを使用した正答率についても確認することができています。既に使用しているモデルがあってもすぐにインポートすることができるため、ForePaaS上でのモデル作成は非常に簡単でした。
今回モデルで使用した説明変数を持つテーブルを用意する必要があるため、boat_race_train_tableを複製したテーブルを作成し、さらに同様のAggregateアクションを作成します。
■Aggregateアクション作成範囲
(2)「boat_race_table」と「boat_race_train_table」を複製します。名前を任意で付けてください。
(3)「boat_race_train_table」を複製したテーブルのInfosをクリックします。[is_higher_second]を削除し、[predict]という文字列型の列を追加して、ビルドします。
■ForePaaS操作画面(TABLES)Aggregateアクション作成1
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成2
(6)ソースは「boat_race_table」を複製したテーブルにして、宛先に「boat_race_train_table」を複製したテーブルを指定します。Predictは予測アクションで値を入れるため、今の段階では削除します。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成3
(8)[DEPLOYMENT]というステップに移動し、Deployment Best Modelをクリックします。
(9)[CONSUMERS]の[ADD]をクリックし、任意の名前をつけ、Typeをテーブルに変更し、「boat_race_train_table」を複製したテーブルを選択します。
■ForePaaS操作画面(MACHINE LEARNING MANAGER)
(10)[DATA PROCESSING ENGINE]>[ACTIONS]にアクセスし、[Machine Learning]タブを開くと、先ほど作成された予測アクションがあるため、編集をクリックします。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成5
(12)右側のSelect an attributeで[predict]を選択し、[RUN]をクリックします。
■ForePaaS操作画面(ACTIONS)Aggregateアクション作成6
全体表示してみると、predict列に1か0の値が入っています!予測結果が格納されていますね。
■ForePaaS操作画面(Queries)予測結果1
■ForePaaS操作画面(Queries)予測結果2
ボートレースの基礎であるインコースが強い傾向などが反映された予測はしてくれていそうですね。
■艇番が1と5の予測結果
(1=A1、2=A2、3=B1、0=B2)
艇番だけでなく階級による傾向もしっかり学習していそうです。階級がB2の場合は2選手のみで極端に少ない気もします。
■ForePaaS操作画面(Queries)予測結果3
■ForePaaS操作画面(Queries)予測結果4
モデルの予測は先ほど見た通りForePaaSのアクションとして作成されるので、データの取り込みと合わせてワークフローに組み込むことで、定期的に自動実行させることができます。
■ワークフロー例
データを収集・加工を自動化し、データを探索、データで学習したモデルを作成して予測という流れを全部ForePaaS上でできました。今回は少し複雑なテキストデータが元データだったため、pythonコードで書いている部分はありますが、CSVやDBなどのデータであればもっと簡単に読み込みからモデル作成までできると思います。
みなさんも、ぜひForePaaSでAIでの予測や分類にチャレンジしてみてはいかがでしょうか!次はAzureやMicrosoft365のデータを使った分析をしてみたいなと思っています。
最後に、JBSではForePaaSのデータ分析実装を継続的に支援するデータ分析ラボ for ForePaaSを提供しております。毎月ご契約いただいた時間を消費することで、要望をいただいた機能を実装および支援を行います。
ForePaaSを活用できるか悩んでいて導入を検討している、ForePaaSを導入したが継続的な機能実装に人手が足りないといった場合にぜひご検討ください。よろしくお願いいたします。
3. 番外編
せっかくForePaaSでモデルを作成しましたので、回収率や的中率を確認したいと思います。
また、ダッシュボードに表示するところまでやってみました。今回のモデル作成の流れを確認するというテーマから離れるため番外編としていますが、これらもすべてForePaaSで作業をしています。
3.1. 回収率と的中率の確認
ForePaaSにはJupyter Notebookが利用できる環境があるため、すぐにpythonでForePaaSのテーブルやバケット内のデータに対してデータ探索することができます。ForePaaSのJupyter Notebook上で、今回作成したモデルをインポートして予測を行い、回収率と的中率を確認してみました。
今回舟券を買う条件を以下としました。
●1レースごとに2位以上になると予想された選手が2人いること(1人や3人の場合は買わない)
●その2選手が1位と2位になると予想して2連複の舟券を購入する
2連複とは・・・
選択した2人の選手がどちらも1位と2位になることで払い戻しが受けられる。1位と2位の順番は問わない。
今回のモデルを使用して2023年3月の全レースで結果を確認します。
■2023年3月全レースでの結果1
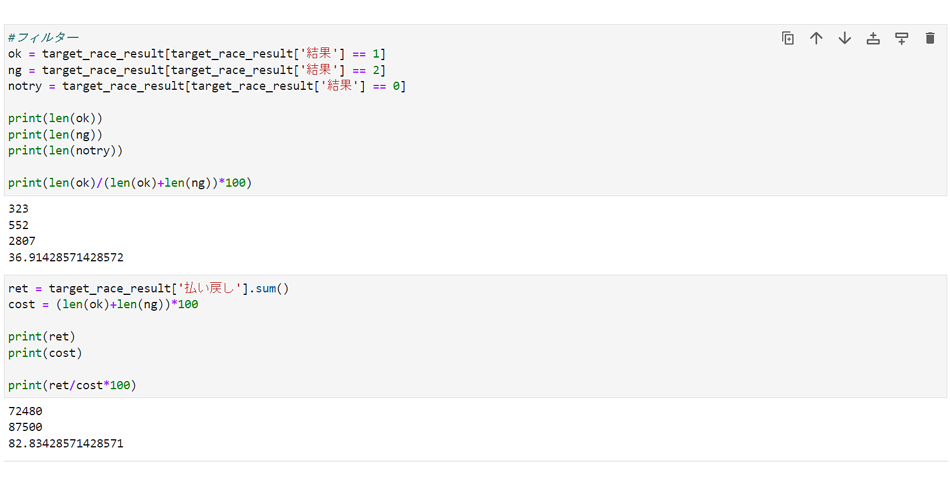 的中率は36%、回収率は82%という結果になりました。
的中率は36%、回収率は82%という結果になりました。
モデル自体の精度は70%となっていましたが、以下のように艇番ごとに2以上になると予測された数を見ると圧倒的に1号艇が多くなっています。
■2023年3月全レースでの結果2
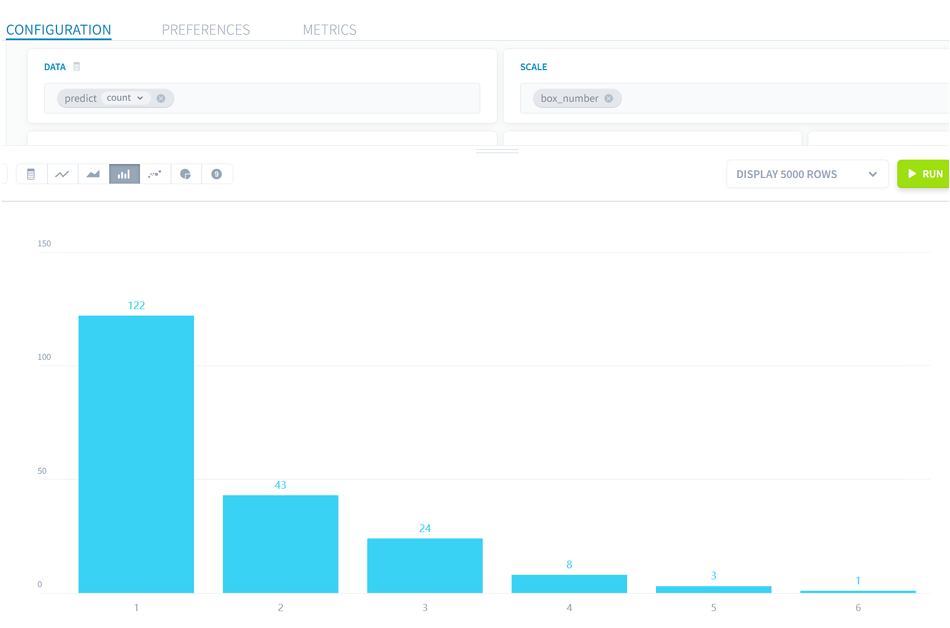 モデルの精度が70%ということから、おそらく1号艇が2位以上になるという予想は当たっており、2連複の買い方であるためもう一方の選手が2位以上になっていないため、的中率は36%になったのだと思います。
モデルの精度が70%ということから、おそらく1号艇が2位以上になるという予想は当たっており、2連複の買い方であるためもう一方の選手が2位以上になっていないため、的中率は36%になったのだと思います。
例えば以下の条件で買った場合
●1レースごとに2位以上になると予想された選手が1人いること(2人以上の場合は買わない)
●その1選手が1位となると予想して単勝の舟券を購入する
単勝とは・・・
選択した1人の選手がどちらも1位になることで払い戻しが受けられる。
■2023年3月全レースでの結果3
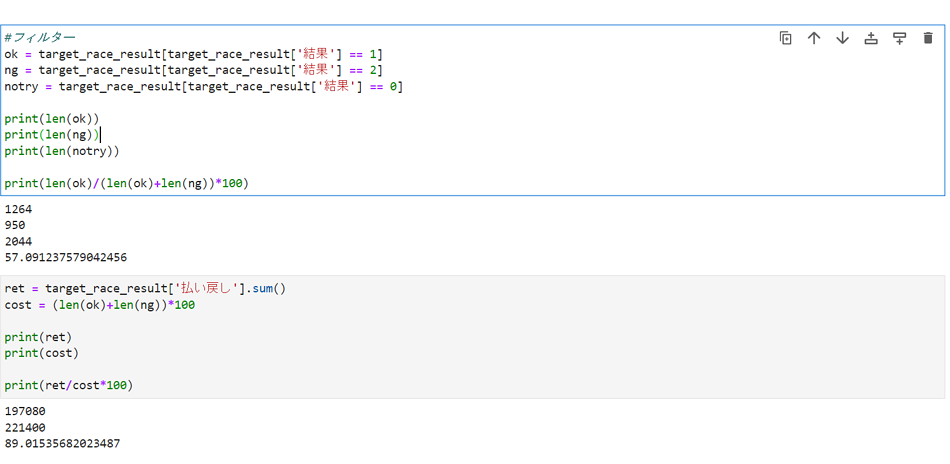 的中率は57%、回収率は89%という結果になりました。
的中率は57%、回収率は89%という結果になりました。
ちなみにこの単勝の条件かつレース場が大村の場合も見てみました。なぜ大村かというと大村のボートレース場はインコースがさらに勝ちやすいと言われているためです。
■2023年3月全レースでの結果4
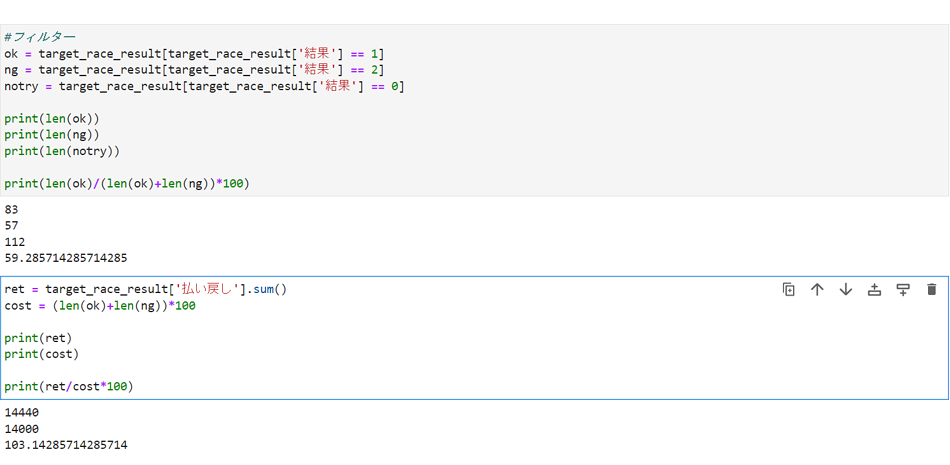 的中率は59%、回収率は103%という結果になりました。
的中率は59%、回収率は103%という結果になりました。
買い方によっては的中率も回収率も増えることが分かりましたが、やはり回収率はもっと増やしたいですね。本来モデルの精度向上のためにさらにデータ加工や他のデータを追加しつつ、買い方についても考えていくという作業が必要になると思います。
3.2. ダッシュボードの表示
予測した値をダッシュボードに表示してみました。予測が1の場合は塗りつぶしの星マークになっています。
■2023年3月全レースでの結果5 ダッシュボードの表示
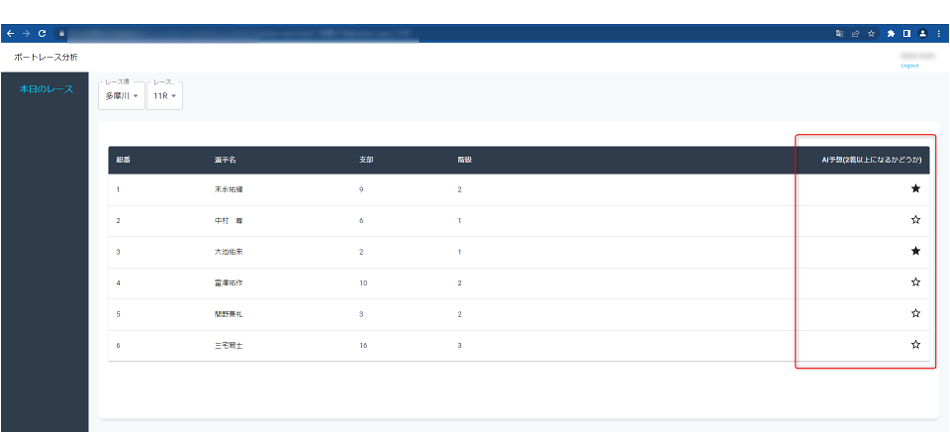 これもForePaaSのアプリ開発機能を利用して表示しています。もっと必要な情報を追加して表示してみたくなりますね。
これもForePaaSのアプリ開発機能を利用して表示しています。もっと必要な情報を追加して表示してみたくなりますね。
3.3. 実践
せっかく画面で最新の予測値が見ることができるようになったので、1日実践してみました。買い方は2連複での回収率での考え方と同様です。
■1日実践した結果
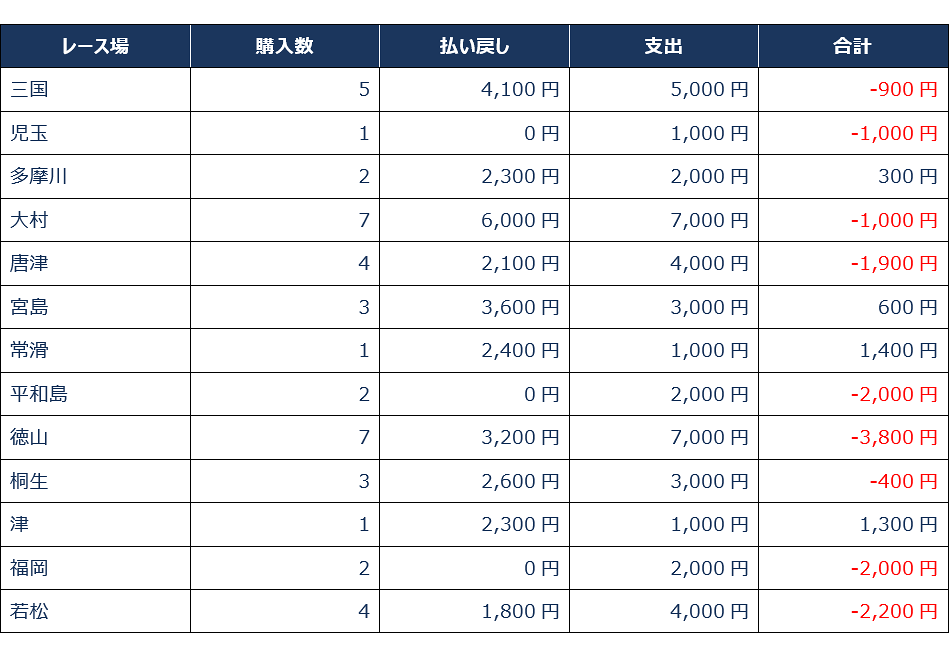 合計収支は-11,600円でした。
合計収支は-11,600円でした。
残念な結果となりましたが、回収率の時点でわかっていたので仕方ないですね。
実際に利用してみて気になったのは以下の2点です。
①やはり1号艇と他選手の組み合わせでしか購入パターンがなかったこと
②的中したものは基本的に2連複のオッズ人気1位であったこと
②については、モデルが過去の結果から学習するためオッズ人気が上位のものを予測することはある意味人間らしい予測となっていて仕方ないのかなと思っています。ただ、1号艇ばかり買っていても厳しいため、的中率はもう少し上げていかないといけません。
予測の結果からどう舟券を買うか、買い方についても検討が必要ですし、事前の展示データや各選手の艇番別の勝率などまだまだ使えそうなデータがたくさんありますので、いつか回収率が満足いくものになるようにアップデートしていきたいです。
また、ダッシュボードに表示するところまでやってみました。今回のモデル作成の流れを確認するというテーマから離れるため番外編としていますが、これらもすべてForePaaSで作業をしています。
今回舟券を買う条件を以下としました。
●1レースごとに2位以上になると予想された選手が2人いること(1人や3人の場合は買わない)
●その2選手が1位と2位になると予想して2連複の舟券を購入する
今回のモデルを使用して2023年3月の全レースで結果を確認します。
■2023年3月全レースでの結果1
モデル自体の精度は70%となっていましたが、以下のように艇番ごとに2以上になると予測された数を見ると圧倒的に1号艇が多くなっています。
■2023年3月全レースでの結果2
例えば以下の条件で買った場合
●1レースごとに2位以上になると予想された選手が1人いること(2人以上の場合は買わない)
●その1選手が1位となると予想して単勝の舟券を購入する
■2023年3月全レースでの結果3
ちなみにこの単勝の条件かつレース場が大村の場合も見てみました。なぜ大村かというと大村のボートレース場はインコースがさらに勝ちやすいと言われているためです。
■2023年3月全レースでの結果4
買い方によっては的中率も回収率も増えることが分かりましたが、やはり回収率はもっと増やしたいですね。本来モデルの精度向上のためにさらにデータ加工や他のデータを追加しつつ、買い方についても考えていくという作業が必要になると思います。
■2023年3月全レースでの結果5 ダッシュボードの表示
■1日実践した結果
残念な結果となりましたが、回収率の時点でわかっていたので仕方ないですね。
実際に利用してみて気になったのは以下の2点です。
①やはり1号艇と他選手の組み合わせでしか購入パターンがなかったこと
②的中したものは基本的に2連複のオッズ人気1位であったこと
②については、モデルが過去の結果から学習するためオッズ人気が上位のものを予測することはある意味人間らしい予測となっていて仕方ないのかなと思っています。ただ、1号艇ばかり買っていても厳しいため、的中率はもう少し上げていかないといけません。
予測の結果からどう舟券を買うか、買い方についても検討が必要ですし、事前の展示データや各選手の艇番別の勝率などまだまだ使えそうなデータがたくさんありますので、いつか回収率が満足いくものになるようにアップデートしていきたいです。
こちらの関連記事も
合わせてお読みください